 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-VAERR: Self-Supervised Apparent Emotional Reaction Recognition from Video
Paper and Code
Oct 20, 2022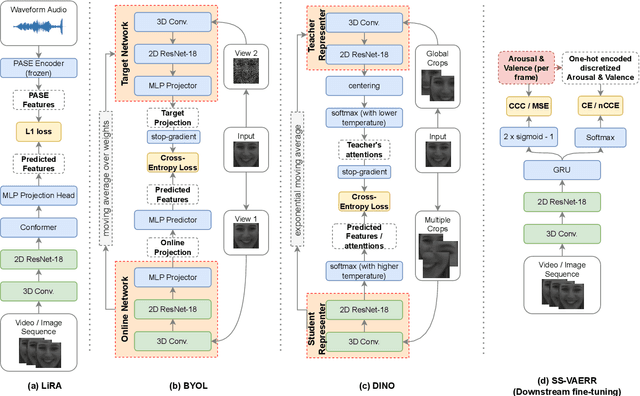

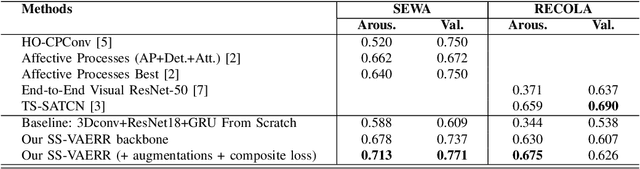
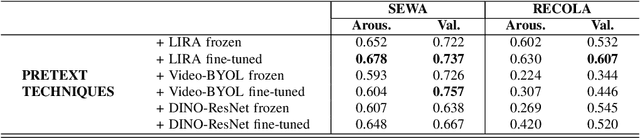
This work focuses on the apparent emotional reaction recognition (AERR) from the video-only input, conducted in a self-supervised fashion. The network is first pre-trained on different self-supervised pretext tasks and later fine-tuned on the downstream target task. Self-supervised learning facilitates the use of pre-trained architectures and larger datasets that might be deemed unfit for the target task and yet might be useful to learn informative representations and hence provide useful initializations for further fine-tuning on smaller more suitable data. Our presented contribution is two-fold: (1) an analysis of different state-of-the-art (SOTA) pretext tasks for the video-only apparent emotional reaction recognition architecture, and (2) an analysis of various combinations of the regression and classification losses that are likely to improve the performance further. Together these two contributions result in the current state-of-the-art performance for the video-only spontaneous apparent emotional reaction recognition with continuous annotations.