Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSR-Affine: High-quality 3D hand model reconstruction from UV Maps
Paper and Code
Feb 07, 2021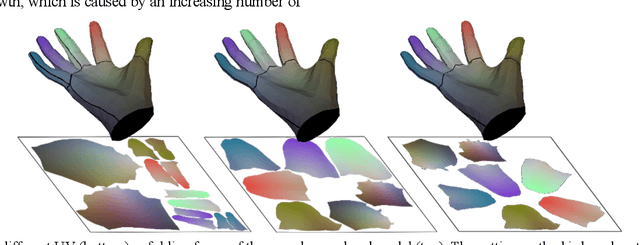

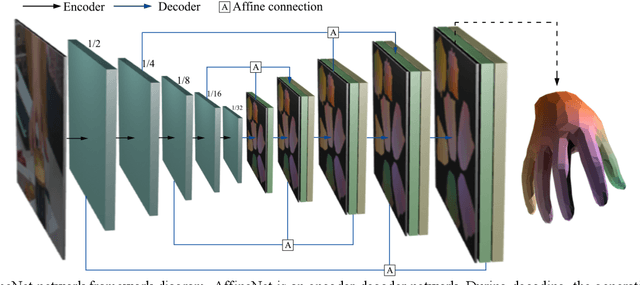

Under various poses and heavy occlusions,3D hand model reconstruction based on a single monocular RGB image has been a challenging problem in computer vision field for many years. In this paper, we propose a SR-Affine approach for high-quality 3D hand model reconstruction. First, we propose an encoder-decoder network architecture (AffineNet) for MANO hand reconstruction. Since MANO hand is not detailed, we further propose SRNet to up-sampling point-clouds by image super-resolution on the UV map. Many experiments demonstrate that our approach is robust and outperforms the state-of-the-art methods on standard benchmarks, including the FreiHAND and HO3D datasets.
* 9 pages, 5 figures
View paper on