Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSquare-root regret bounds for continuous-time episodic Markov decision processes
Paper and Code
Oct 03, 2022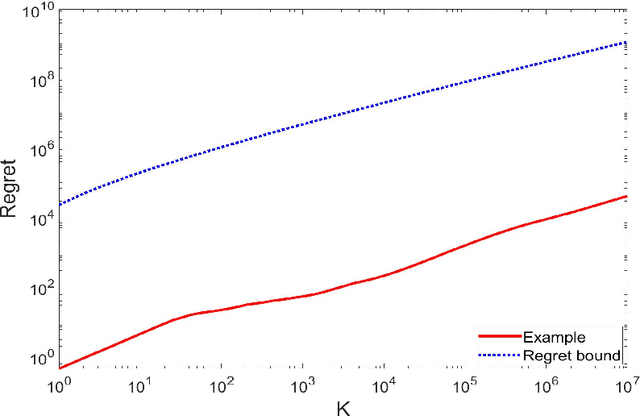
We study reinforcement learning for continuous-time Markov decision processes (MDPs) in the finite-horizon episodic setting. We present a learning algorithm based on the methods of value iteration and upper confidence bound. We derive an upper bound on the worst-case expected regret for the proposed algorithm, and establish a worst-case lower bound, both bounds are of the order of square-root on the number of episodes. Finally, we conduct simulation experiments to illustrate the performance of our algorithm.
View paper on