 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing?
Paper and Code
Feb 19, 2024
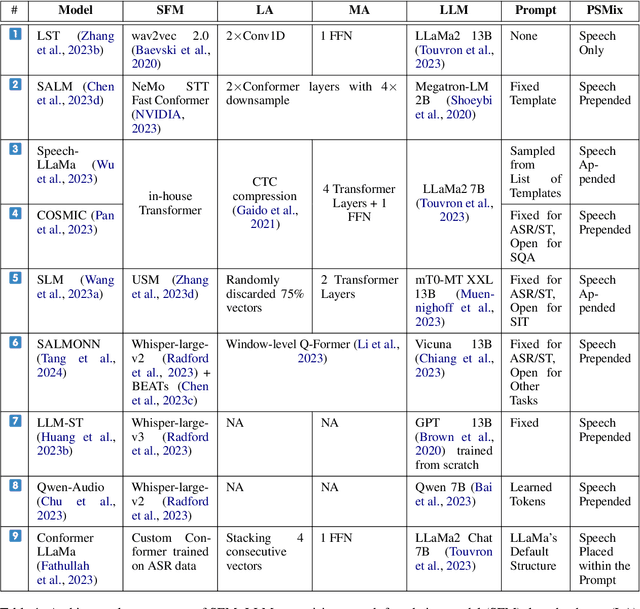


The field of natural language processing (NLP) has recently witnessed a transformative shift with the emergence of foundation models, particularly Large Language Models (LLMs) that have revolutionized text-based NLP. This paradigm has extended to other modalities, including speech, where researchers are actively exploring the combination of Speech Foundation Models (SFMs) and LLMs into single, unified models capable of addressing multimodal tasks. Among such tasks, this paper focuses on speech-to-text translation (ST). By examining the published papers on the topic, we propose a unified view of the architectural solutions and training strategies presented so far, highlighting similarities and differences among them. Based on this examination, we not only organize the lessons learned but also show how diverse settings and evaluation approaches hinder the identification of the best-performing solution for each architectural building block and training choice. Lastly, we outline recommendations for future works on the topic aimed at better understanding the strengths and weaknesses of the SFM+LLM solutions for ST.