 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech to Text Adaptation: Towards an Efficient Cross-Modal Distillation
Paper and Code
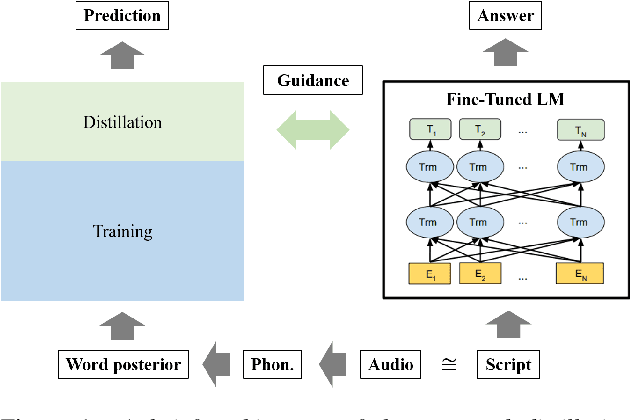
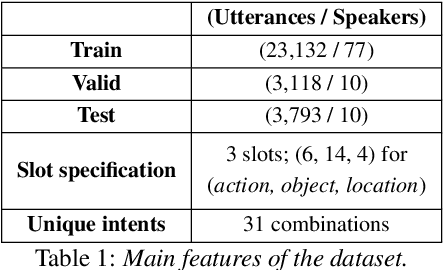
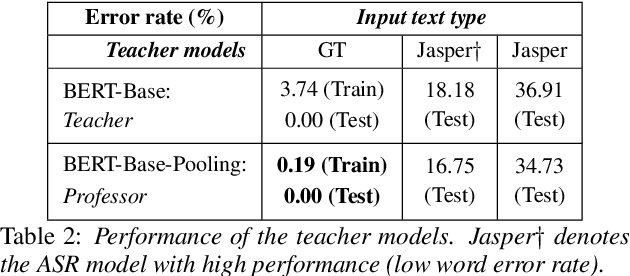
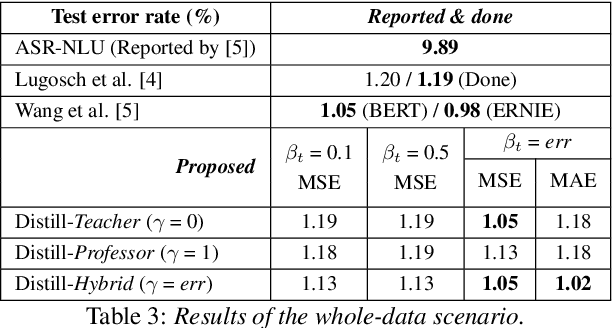
Speech is one of the most effective means of communication and is full of information that helps the transmission of utterer's thoughts. However, mainly due to the cumbersome processing of acoustic features, phoneme or word posterior probability has frequently been discarded in understanding the natural language. Thus, some recent spoken language understanding (SLU) modules have utilized an end-to-end structure that preserves the uncertainty information. This further reduces the propagation of speech recognition error and guarantees computational efficiency. We claim that in this process, the speech comprehension can benefit from the inference of massive pre-trained language models (LMs). We transfer the knowledge from a concrete Transformer-based text LM to an SLU module which can face a data shortage, based on recent cross-modal distillation methodologies. We demonstrate the validity of our proposal upon the performance on the Fluent Speech Command dataset. Thereby, we experimentally verify our hypothesis that the knowledge could be shared from the top layer of the LM to a fully speech-based module, in which the abstracted speech is expected to meet the semantic representation.