 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum Dependent Learning Curves in Kernel Regression and Wide Neural Networks
Paper and Code


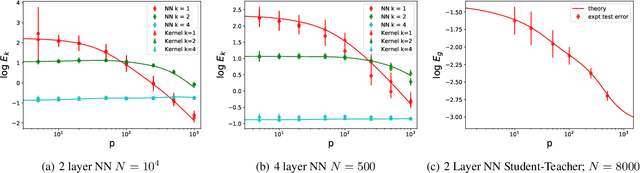

A fundamental question in modern machine learning is how deep neural networks can generalize. We address this question using 1) an equivalence between training infinitely wide neural networks and performing kernel regression with a deterministic kernel called the Neural Tangent Kernel (NTK) (Jacot et al. 2018), and 2) theoretical tools from statistical physics. We derive analytical expressions for learning curves for kernel regression, and use them to evaluate how the test loss of a trained neural network depends on the number of samples. Our approach allows us not only to compute the total test risk but also the decomposition of the risk due to different spectral components of the kernel. Complementary to recent results showing that during gradient descent, neural networks fit low frequency components first, we identify a new type of frequency principle: as the size of the training set size grows, kernel machines and neural networks begin to fit successively higher frequency modes of the target function. We verify our theory with simulations of kernel regression and training wide artificial neural networks.