 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecializing Multilingual Language Models: An Empirical Study
Paper and Code

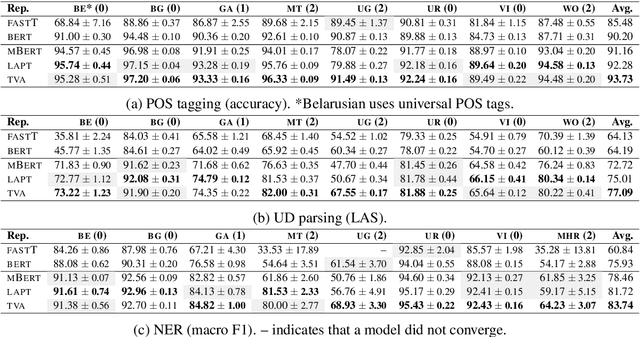


Contextualized word representations from pretrained multilingual language models have become the de facto standard for addressing natural language tasks in many different languages, but the success of this approach is far from universal. For languages rarely or never seen by these models, directly using such models often results in suboptimal representation or use of data, motivating additional model adaptations to achieve reasonably strong performance. In this work, we study the performance, extensibility, and interaction of two such adaptations for this low-resource setting: vocabulary augmentation and script transliteration. Our evaluations on a set of three tasks in nine diverse low-resource languages yield a mixed result, upholding the viability of these approaches while raising new questions around how to optimally adapt multilingual models to low-resource settings.