 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking the Same Language: Matching Machine to Human Captions by Adversarial Training
Paper and Code

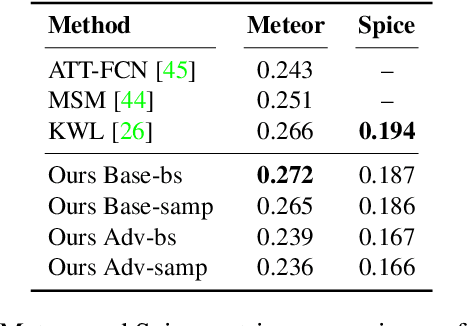
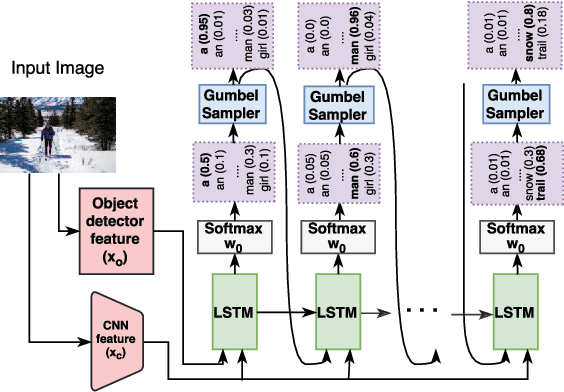
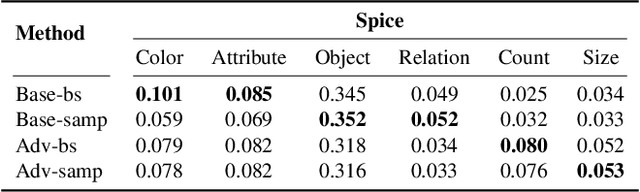
While strong progress has been made in image captioning over the last years, machine and human captions are still quite distinct. A closer look reveals that this is due to the deficiencies in the generated word distribution, vocabulary size, and strong bias in the generators towards frequent captions. Furthermore, humans -- rightfully so -- generate multiple, diverse captions, due to the inherent ambiguity in the captioning task which is not considered in today's systems. To address these challenges, we change the training objective of the caption generator from reproducing groundtruth captions to generating a set of captions that is indistinguishable from human generated captions. Instead of handcrafting such a learning target, we employ adversarial training in combination with an approximate Gumbel sampler to implicitly match the generated distribution to the human one. While our method achieves comparable performance to the state-of-the-art in terms of the correctness of the captions, we generate a set of diverse captions, that are significantly less biased and match the word statistics better in several aspects.