 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker verification-derived loss and data augmentation for DNN-based multispeaker speech synthesis
Paper and Code
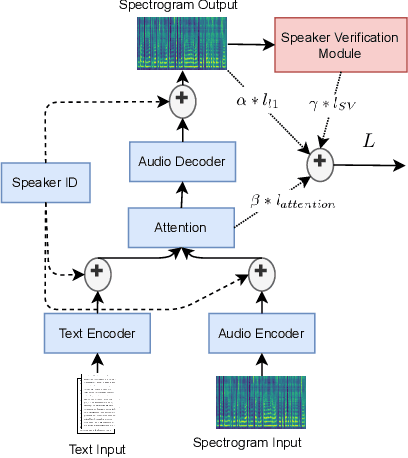


Building multispeaker neural network-based text-to-speech synthesis systems commonly relies on the availability of large amounts of high quality recordings from each speaker and conditioning the training process on the speaker's identity or on a learned representation of it. However, when little data is available from each speaker, or the number of speakers is limited, the multispeaker TTS can be hard to train and will result in poor speaker similarity and naturalness. In order to address this issue, we explore two directions: forcing the network to learn a better speaker identity representation by appending an additional loss term; and augmenting the input data pertaining to each speaker using waveform manipulation methods. We show that both methods are efficient when evaluated with both objective and subjective measures. The additional loss term aids the speaker similarity, while the data augmentation improves the intelligibility of the multispeaker TTS system.