 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal Features for Generalized Detection of Deepfake Videos
Paper and Code
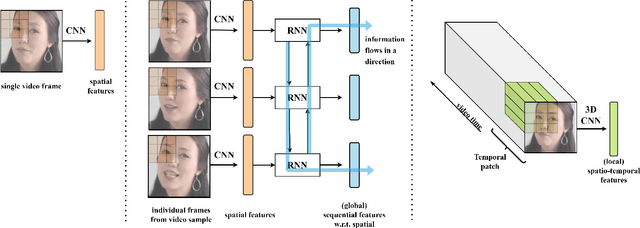

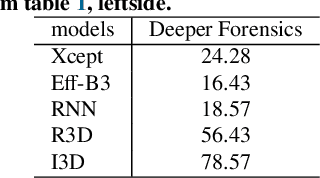
For deepfake detection, video-level detectors have not been explored as extensively as image-level detectors, which do not exploit temporal data. In this paper, we empirically show that existing approaches on image and sequence classifiers generalize poorly to new manipulation techniques. To this end, we propose spatio-temporal features, modeled by 3D CNNs, to extend the generalization capabilities to detect new sorts of deepfake videos. We show that spatial features learn distinct deepfake-method-specific attributes, while spatio-temporal features capture shared attributes between deepfake methods. We provide an in-depth analysis of how the sequential and spatio-temporal video encoders are utilizing temporal information using DFDC dataset arXiv:2006.07397. Thus, we unravel that our approach captures local spatio-temporal relations and inconsistencies in the deepfake videos while existing sequence encoders are indifferent to it. Through large scale experiments conducted on the FaceForensics++ arXiv:1901.08971 and Deeper Forensics arXiv:2001.03024 datasets, we show that our approach outperforms existing methods in terms of generalization capabilities.