 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-attentive Graphs for Human-Object Interaction Detection
Paper and Code

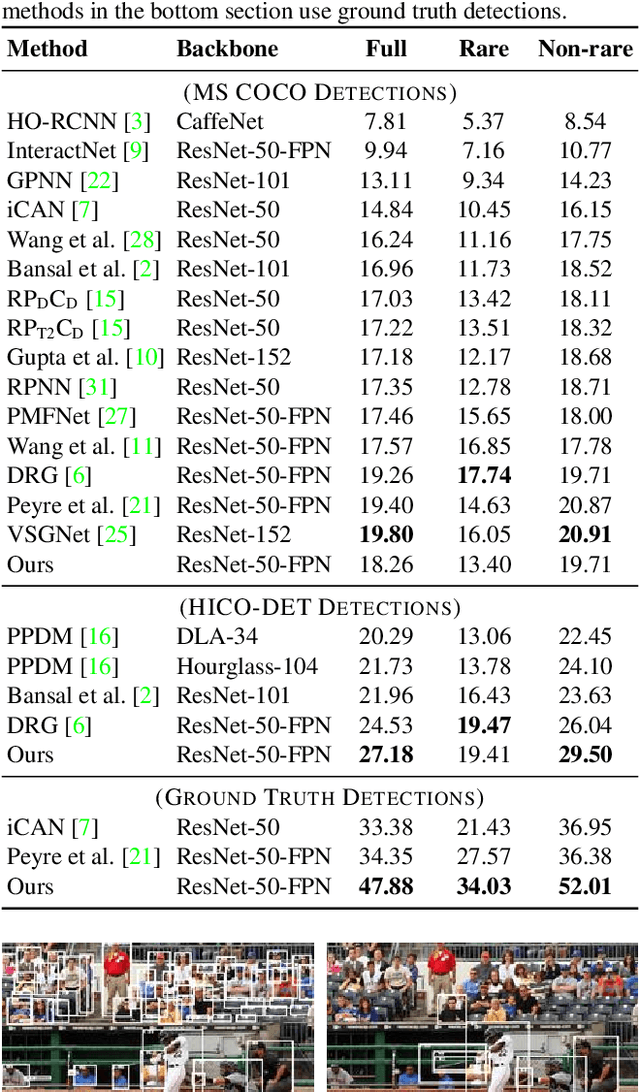
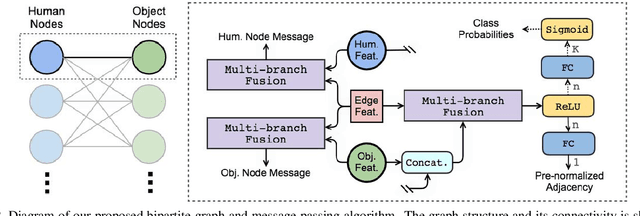
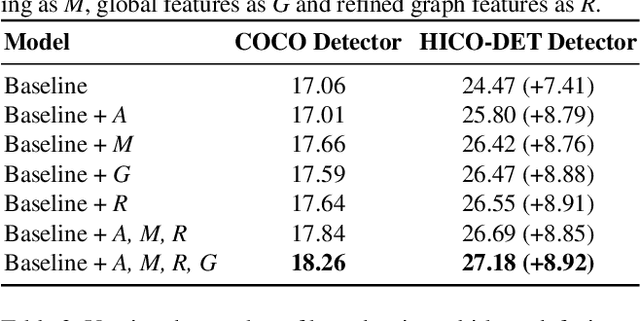
We address the problem of detecting human--object interactions in images using graphical neural networks. Our network constructs a bipartite graph of nodes representing detected humans and objects, wherein messages passed between the nodes encode relative spatial and appearance information. Unlike existing approaches that separate appearance and spatial features, our method fuses these two cues within a single graphical model allowing information conditioned on both modalities to influence the prediction of interactions with neighboring nodes. Through extensive experimentation we demonstrate the advantages of fusing relative spatial information with appearance features in the computation of adjacency structure, message passing and the ultimate refined graph features. On the popular HICO-DET benchmark dataset, our model outperforms state-of-the-art with an mAP of 27.18, a 10% relative improvement.