Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsifying Transformer Models with Differentiable Representation Pooling
Paper and Code
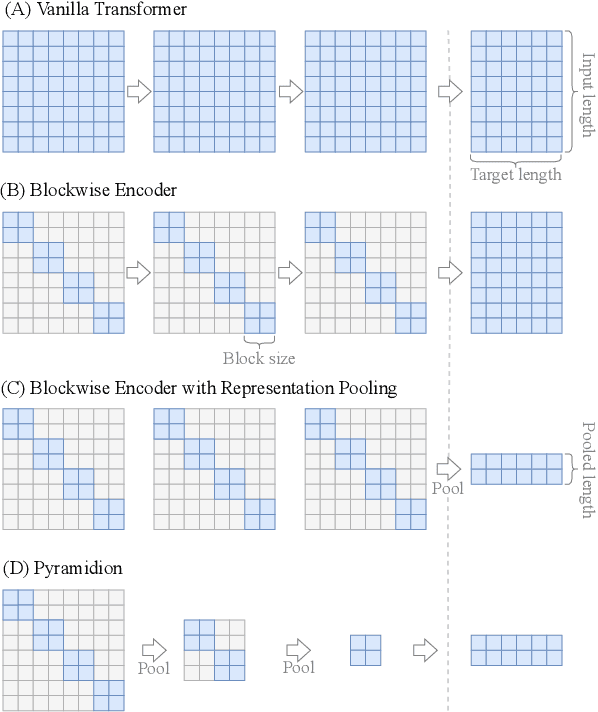
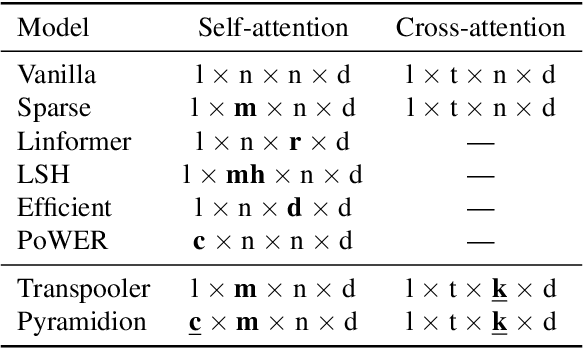
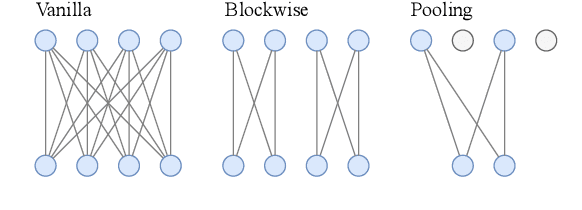
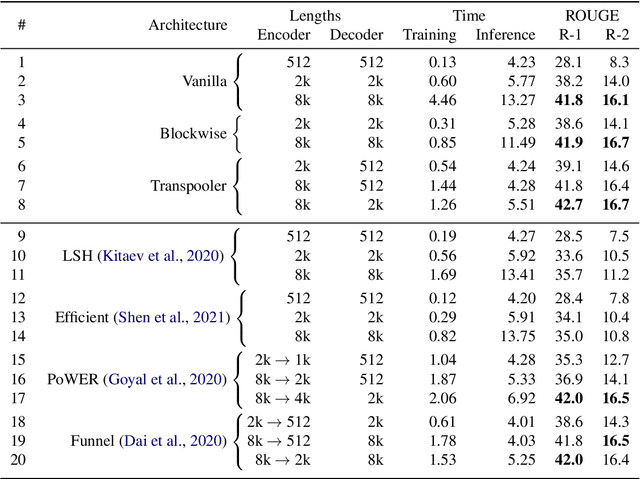
We propose a novel method to sparsify attention in the Transformer model by learning to select the most-informative token representations, thus leveraging the model's information bottleneck with twofold strength. A careful analysis shows that the contextualization of encoded representations in our model is significantly more effective than in the original Transformer. We achieve a notable reduction in memory usage due to an improved differentiable top-k operator, making the model suitable to process long documents, as shown on an example of a summarization task.
View paper on