 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Representation of Multivariate Extremes with Applications to Anomaly Ranking
Paper and Code
Mar 31, 2016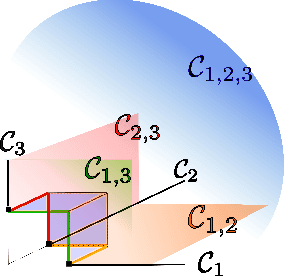
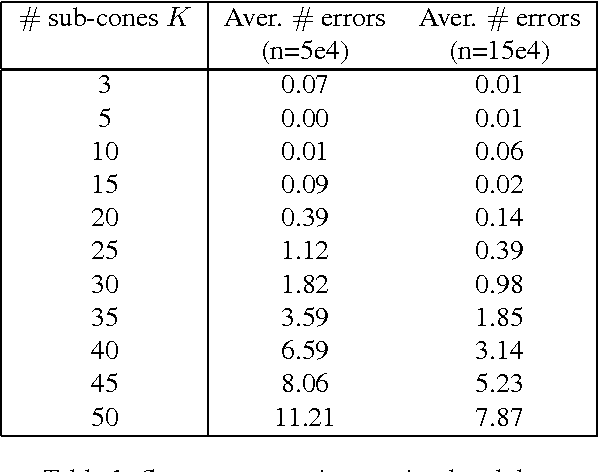
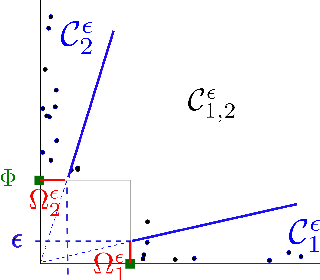
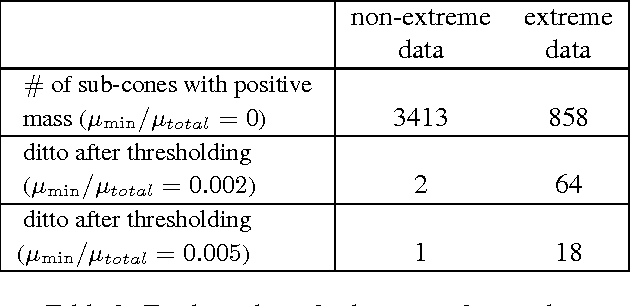
Extremes play a special role in Anomaly Detection. Beyond inference and simulation purposes, probabilistic tools borrowed from Extreme Value Theory (EVT), such as the angular measure, can also be used to design novel statistical learning methods for Anomaly Detection/ranking. This paper proposes a new algorithm based on multivariate EVT to learn how to rank observations in a high dimensional space with respect to their degree of 'abnormality'. The procedure relies on an original dimension-reduction technique in the extreme domain that possibly produces a sparse representation of multivariate extremes and allows to gain insight into the dependence structure thereof, escaping the curse of dimensionality. The representation output by the unsupervised methodology we propose here can be combined with any Anomaly Detection technique tailored to non-extreme data. As it performs linearly with the dimension and almost linearly in the data (in O(dn log n)), it fits to large scale problems. The approach in this paper is novel in that EVT has never been used in its multivariate version in the field of Anomaly Detection. Illustrative experimental results provide strong empirical evidence of the relevance of our approach.