 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Centroid-Encoder: A Nonlinear Model for Feature Selection
Paper and Code
Jan 30, 2022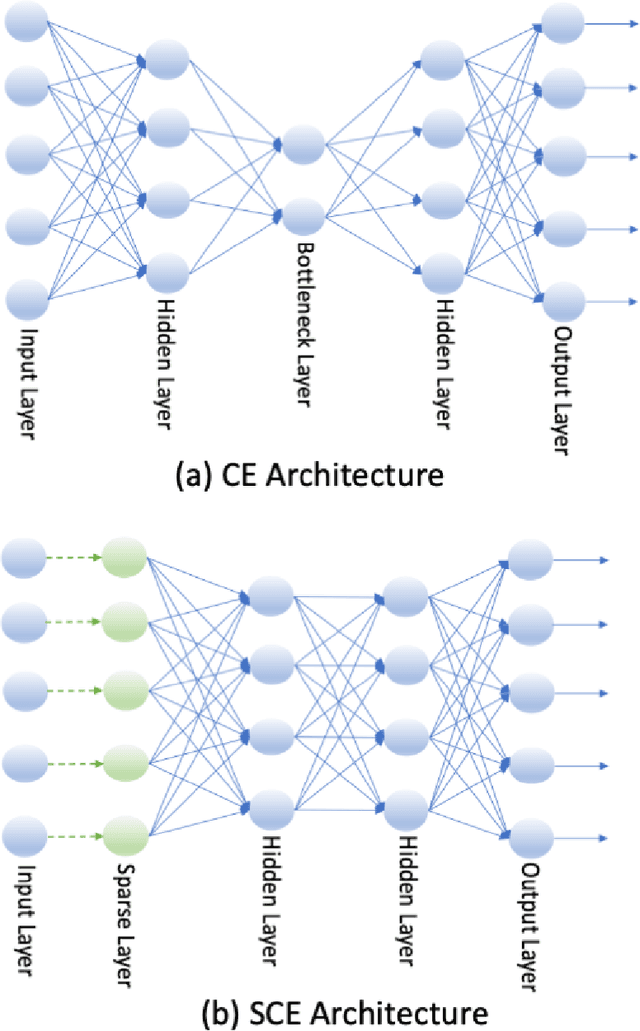


We develop a sparse optimization problem for the determination of the total set of features that discriminate two or more classes. This is a sparse implementation of the centroid-encoder for nonlinear data reduction and visualization called Sparse Centroid-Encoder (SCE). We also provide a feature selection framework that first ranks each feature by its occurrence, and the optimal number of features is chosen using a validation set. The algorithm is applied to a wide variety of data sets including, single-cell biological data, high dimensional infectious disease data, hyperspectral data, image data, and speech data. We compared our method to various state-of-the-art feature selection techniques, including two neural network-based models (DFS, and LassoNet), Sparse SVM, and Random Forest. We empirically showed that SCE features produced better classification accuracy on the unseen test data, often with fewer features.