 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNR-based teachers-student technique for speech enhancement
Paper and Code
May 29, 2020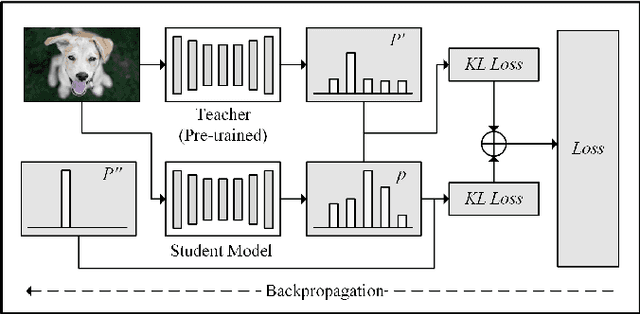
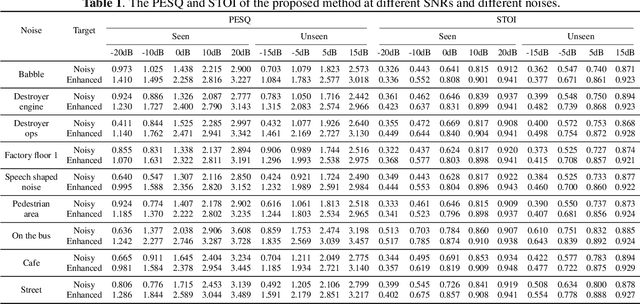
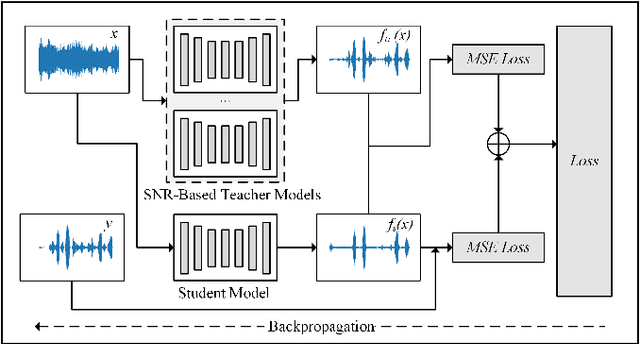
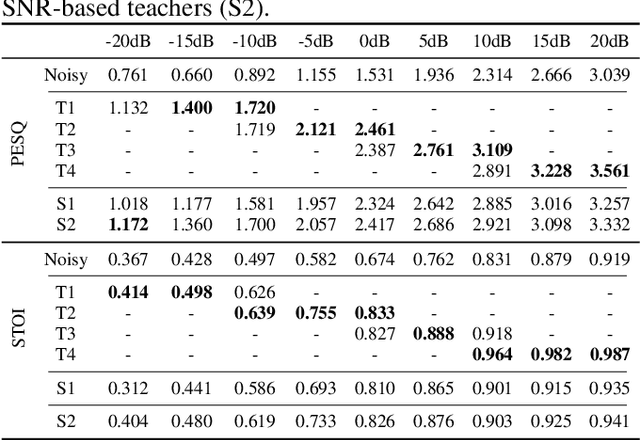
It is very challenging for speech enhancement methods to achieves robust performance under both high signal-to-noise ratio (SNR) and low SNR simultaneously. In this paper, we propose a method that integrates an SNR-based teachers-student technique and time-domain U-Net to deal with this problem. Specifically, this method consists of multiple teacher models and a student model. We first train the teacher models under multiple small-range SNRs that do not coincide with each other so that they can perform speech enhancement well within the specific SNR range. Then, we choose different teacher models to supervise the training of the student model according to the SNR of the training data. Eventually, the student model can perform speech enhancement under both high SNR and low SNR. To evaluate the proposed method, we constructed a dataset with an SNR ranging from -20dB to 20dB based on the public dataset. We experimentally analyzed the effectiveness of the SNR-based teachers-student technique and compared the proposed method with several state-of-the-art methods.