 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothness-Aware Quantization Techniques
Paper and Code
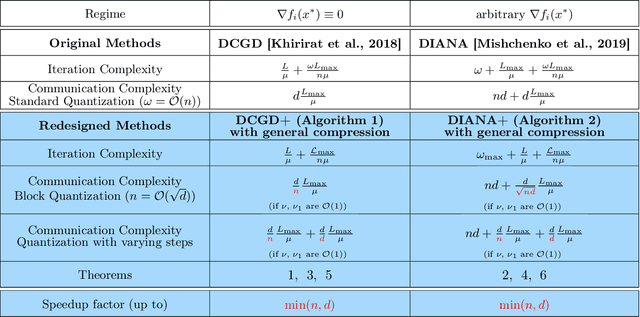
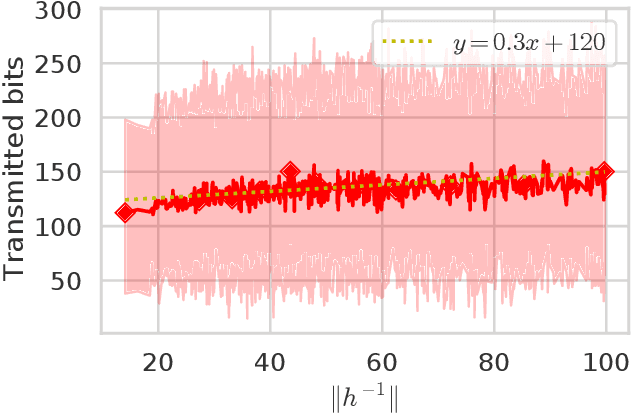
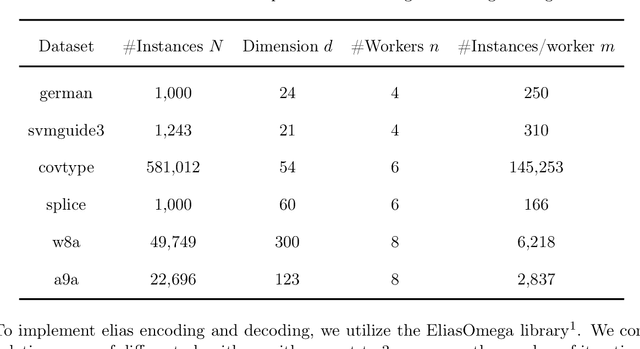
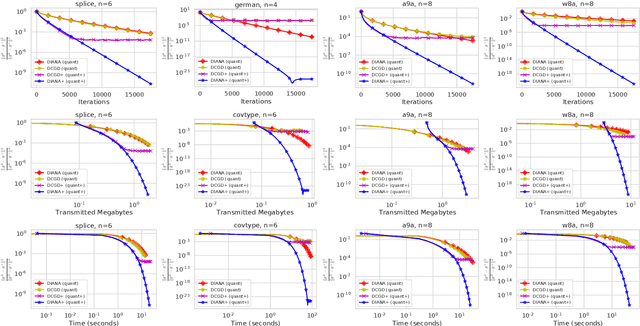
Distributed machine learning has become an indispensable tool for training large supervised machine learning models. To address the high communication costs of distributed training, which is further exacerbated by the fact that modern highly performing models are typically overparameterized, a large body of work has been devoted in recent years to the design of various compression strategies, such as sparsification and quantization, and optimization algorithms capable of using them. Recently, Safaryan et al (2021) pioneered a dramatically different compression design approach: they first use the local training data to form local {\em smoothness matrices}, and then propose to design a compressor capable of exploiting the smoothness information contained therein. While this novel approach leads to substantial savings in communication, it is limited to sparsification as it crucially depends on the linearity of the compression operator. In this work, we resolve this problem by extending their smoothness-aware compression strategy to arbitrary unbiased compression operators, which also includes sparsification. Specializing our results to quantization, we observe significant savings in communication complexity compared to standard quantization. In particular, we show theoretically that block quantization with $n$ blocks outperforms single block quantization, leading to a reduction in communication complexity by an $\mathcal{O}(n)$ factor, where $n$ is the number of nodes in the distributed system. Finally, we provide extensive numerical evidence that our smoothness-aware quantization strategies outperform existing quantization schemes as well the aforementioned smoothness-aware sparsification strategies with respect to all relevant success measures: the number of iterations, the total amount of bits communicated, and wall-clock time.