 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth over-parameterized solvers for non-smooth structured optimization
Paper and Code
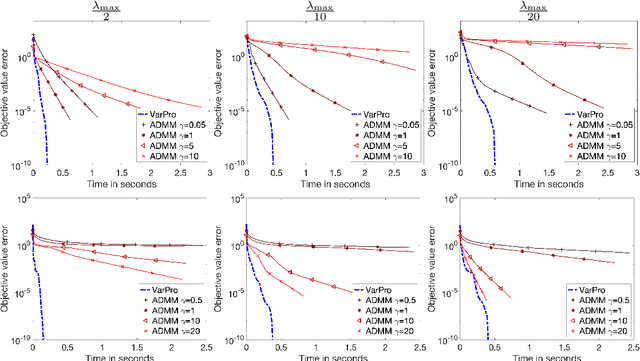
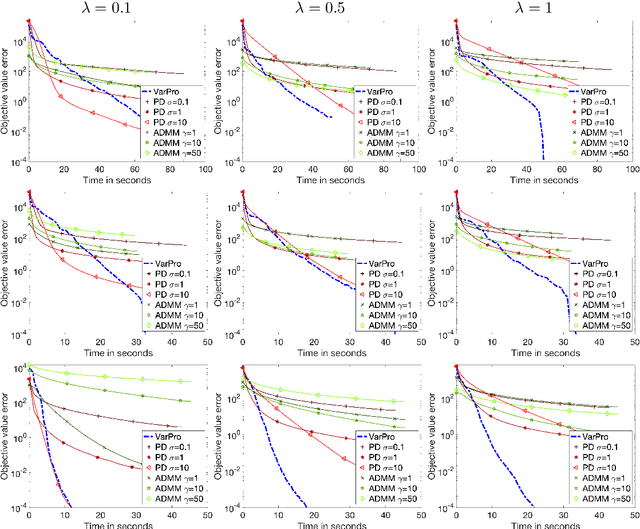

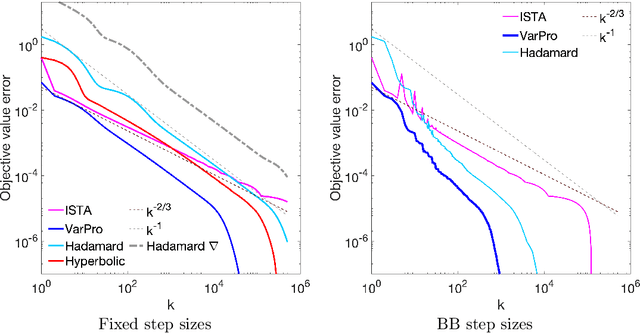
Non-smooth optimization is a core ingredient of many imaging or machine learning pipelines. Non-smoothness encodes structural constraints on the solutions, such as sparsity, group sparsity, low-rank and sharp edges. It is also the basis for the definition of robust loss functions and scale-free functionals such as square-root Lasso. Standard approaches to deal with non-smoothness leverage either proximal splitting or coordinate descent. These approaches are effective but usually require parameter tuning, preconditioning or some sort of support pruning. In this work, we advocate and study a different route, which operates a non-convex but smooth over-parametrization of the underlying non-smooth optimization problems. This generalizes quadratic variational forms that are at the heart of the popular Iterative Reweighted Least Squares (IRLS). Our main theoretical contribution connects gradient descent on this reformulation to a mirror descent flow with a varying Hessian metric. This analysis is crucial to derive convergence bounds that are dimension-free. This explains the efficiency of the method when using small grid sizes in imaging. Our main algorithmic contribution is to apply the Variable Projection (VarPro) method which defines a new formulation by explicitly minimizing over part of the variables. This leads to a better conditioning of the minimized functional and improves the convergence of simple but very efficient gradient-based methods, for instance quasi-Newton solvers. We exemplify the use of this new solver for the resolution of regularized regression problems for inverse problems and supervised learning, including total variation prior and non-convex regularizers.