 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMC++: Masked Learning of Unsupervised Video Semantic Compression
Paper and Code



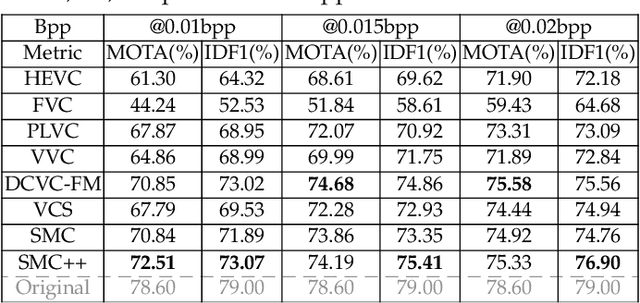
Most video compression methods focus on human visual perception, neglecting semantic preservation. This leads to severe semantic loss during the compression, hampering downstream video analysis tasks. In this paper, we propose a Masked Video Modeling (MVM)-powered compression framework that particularly preserves video semantics, by jointly mining and compressing the semantics in a self-supervised manner. While MVM is proficient at learning generalizable semantics through the masked patch prediction task, it may also encode non-semantic information like trivial textural details, wasting bitcost and bringing semantic noises. To suppress this, we explicitly regularize the non-semantic entropy of the compressed video in the MVM token space. The proposed framework is instantiated as a simple Semantic-Mining-then-Compression (SMC) model. Furthermore, we extend SMC as an advanced SMC++ model from several aspects. First, we equip it with a masked motion prediction objective, leading to better temporal semantic learning ability. Second, we introduce a Transformer-based compression module, to improve the semantic compression efficacy. Considering that directly mining the complex redundancy among heterogeneous features in different coding stages is non-trivial, we introduce a compact blueprint semantic representation to align these features into a similar form, fully unleashing the power of the Transformer-based compression module. Extensive results demonstrate the proposed SMC and SMC++ models show remarkable superiority over previous traditional, learnable, and perceptual quality-oriented video codecs, on three video analysis tasks and seven datasets. \textit{Codes and model are available at: \url{https://github.com/tianyuan168326/VideoSemanticCompression-Pytorch}.