 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Footprint Multi-channel ConvMixer for Keyword Spotting with Centroid Based Awareness
Paper and Code
Apr 11, 2022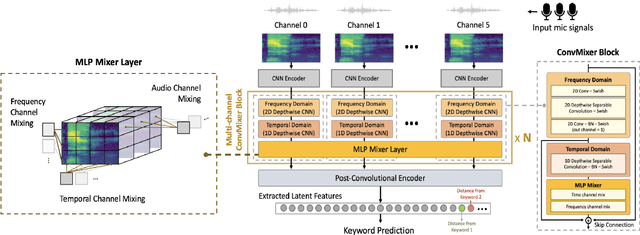
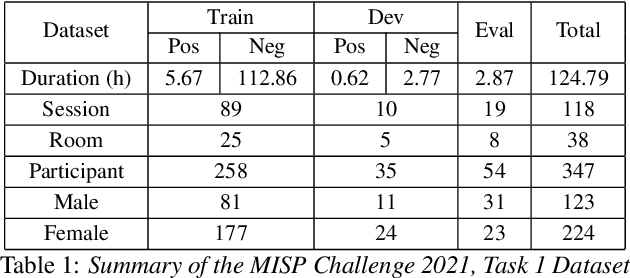
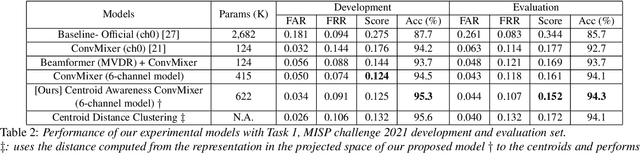
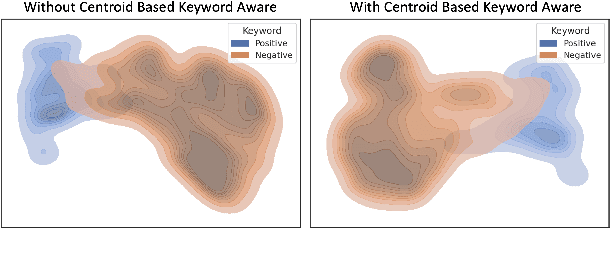
It is critical for a keyword spotting model to have a small footprint as it typically runs on-device with low computational resources. However, maintaining the previous SOTA performance with reduced model size is challenging. In addition, a far-field and noisy environment with multiple signals interference aggravates the problem causing the accuracy to degrade significantly. In this paper, we present a multi-channel ConvMixer for speech command recognitions. The novel architecture introduces an additional audio channel mixing for channel audio interaction in a multi-channel audio setting to achieve better noise-robust features with more efficient computation. Besides, we proposed a centroid based awareness component to enhance the system by equipping it with additional spatial geometry information in the latent feature projection space. We evaluate our model using the new MISP challenge 2021 dataset. Our model achieves significant improvement against the official baseline with a 55% gain in the competition score (0.152) on raw microphone array input and a 63% (0.126) boost upon front-end speech enhancement.