 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Rating for Generative Models
Paper and Code
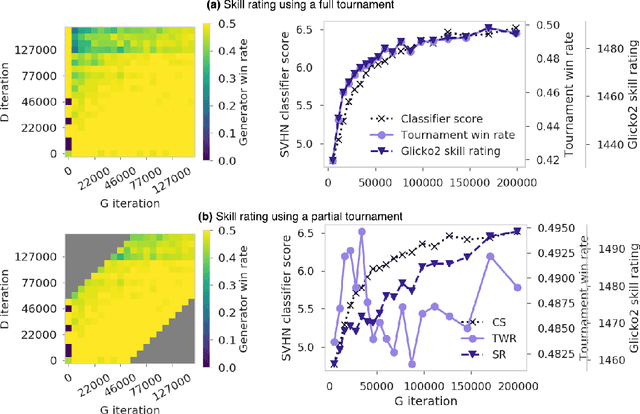
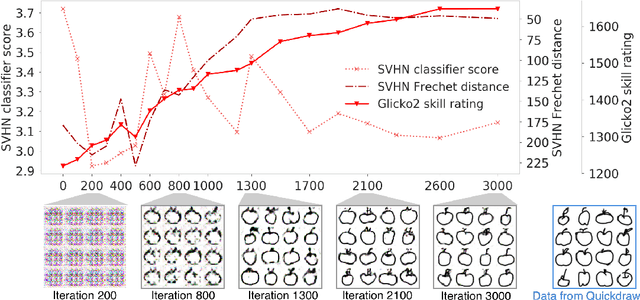
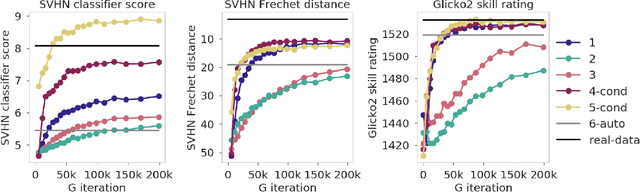

We explore a new way to evaluate generative models using insights from evaluation of competitive games between human players. We show experimentally that tournaments between generators and discriminators provide an effective way to evaluate generative models. We introduce two methods for summarizing tournament outcomes: tournament win rate and skill rating. Evaluations are useful in different contexts, including monitoring the progress of a single model as it learns during the training process, and comparing the capabilities of two different fully trained models. We show that a tournament consisting of a single model playing against past and future versions of itself produces a useful measure of training progress. A tournament containing multiple separate models (using different seeds, hyperparameters, and architectures) provides a useful relative comparison between different trained GANs. Tournament-based rating methods are conceptually distinct from numerous previous categories of approaches to evaluation of generative models, and have complementary advantages and disadvantages.