 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingular Values for ReLU Layers
Paper and Code
Dec 06, 2018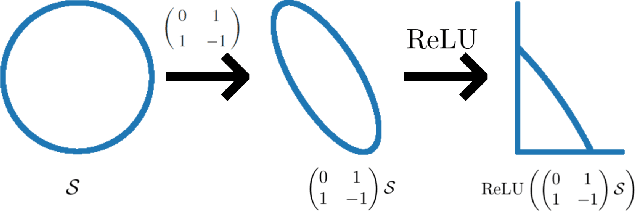
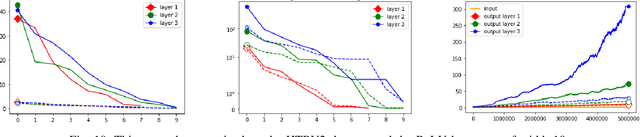
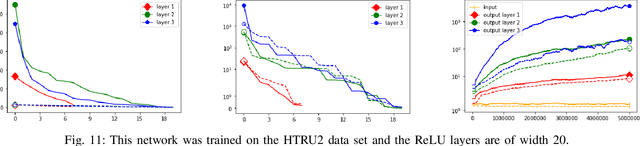
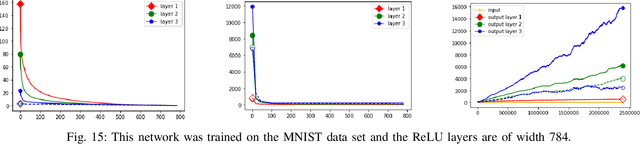
Despite their prevalence in neural networks we still lack a thorough theoretical characterization of ReLU layers. This paper aims to further our understanding of ReLU layers by studying how the activation function ReLU interacts with the linear component of the layer and what role this interaction plays in the success of the neural network in achieving its intended task. To this end, we introduce two new tools: ReLU singular values of operators and the Gaussian mean width of operators. By presenting on the one hand theoretical justifications, results, and interpretations of these two concepts and on the other hand numerical experiments and results of the ReLU singular values and the Gaussian mean width being applied to trained neural networks, we hope to give a comprehensive, singular-value-centric view of ReLU layers. We find that ReLU singular values and the Gaussian mean width do not only enable theoretical insights, but also provide one with metrics which seem promising for practical applications. In particular, these measures can be used to distinguish correctly and incorrectly classified data as it traverses the network. We conclude by introducing two tools based on our findings: double-layers and harmonic pruning.