 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Shared Network with Prior-Inspired Loss for Parameter-Efficient Multi-Modal Imaging Skin Lesion Classification
Paper and Code
Mar 28, 2024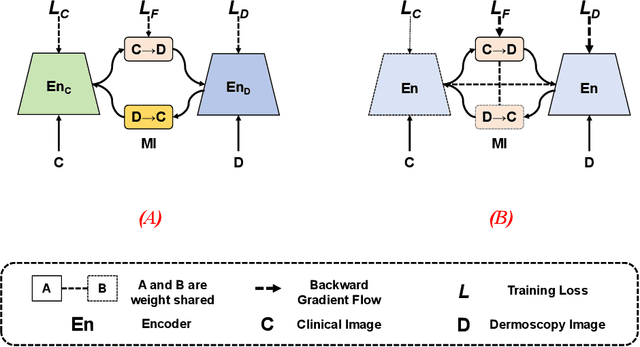

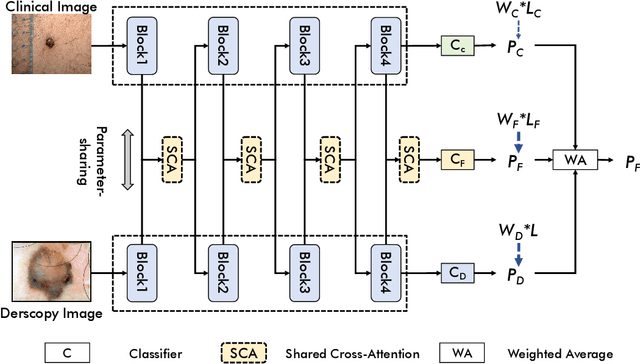

In this study, we introduce a multi-modal approach that efficiently integrates multi-scale clinical and dermoscopy features within a single network, thereby substantially reducing model parameters. The proposed method includes three novel fusion schemes. Firstly, unlike current methods that usually employ two individual models for for clinical and dermoscopy modalities, we verified that multimodal feature can be learned by sharing the parameters of encoder while leaving the individual modal-specific classifiers. Secondly, the shared cross-attention module can replace the individual one to efficiently interact between two modalities at multiple layers. Thirdly, different from current methods that equally optimize dermoscopy and clinical branches, inspired by prior knowledge that dermoscopy images play a more significant role than clinical images, we propose a novel biased loss. This loss guides the single-shared network to prioritize dermoscopy information over clinical information, implicitly learning a better joint feature representation for the modal-specific task. Extensive experiments on a well-recognized Seven-Point Checklist (SPC) dataset and a collected dataset demonstrate the effectiveness of our method on both CNN and Transformer structures. Furthermore, our method exhibits superiority in both accuracy and model parameters compared to currently advanced methods.