 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle headed attention based sequence-to-sequence model for state-of-the-art results on Switchboard-300
Paper and Code
Jan 20, 2020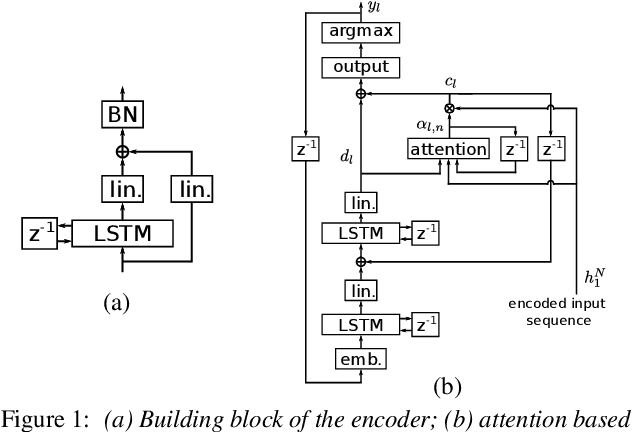
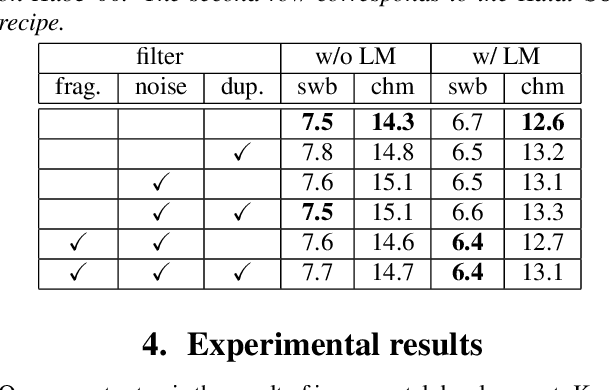
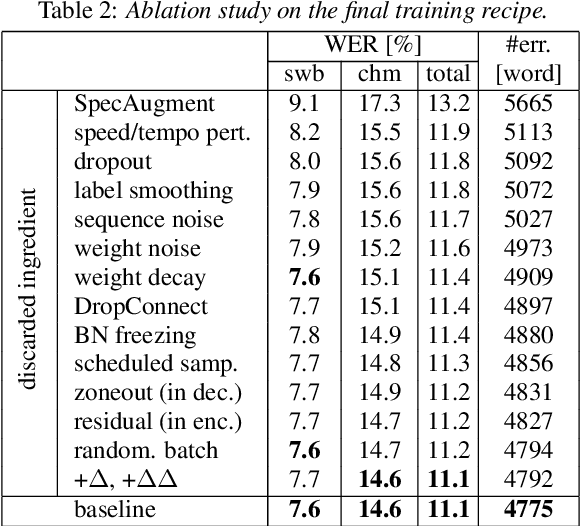
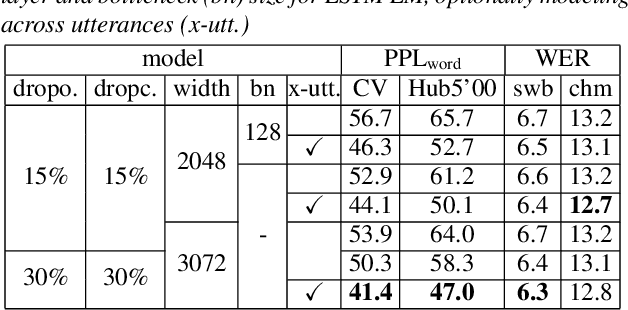
It is generally believed that direct sequence-to-sequence (seq2seq) speech recognition models are competitive with hybrid models only when a large amount of data, at least a thousand hours, is available for training. In this paper, we show that state-of-the-art recognition performance can be achieved on the Switchboard-300 database using a single headed attention, LSTM based model. Using a cross-utterance language model, our single-pass speaker independent system reaches 6.4% and 12.5% word error rate (WER) on the Switchboard and CallHome subsets of Hub5'00, without a pronunciation lexicon. While careful regularization and data augmentation are crucial in achieving this level of performance, experiments on Switchboard-2000 show that nothing is more useful than more data.