 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-dataset Experts for Multi-dataset Question Answering
Paper and Code
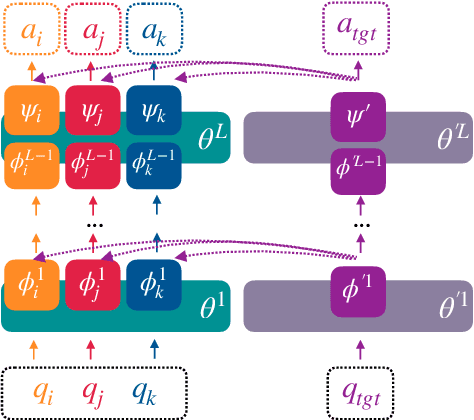

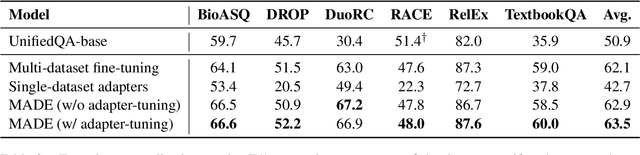

Many datasets have been created for training reading comprehension models, and a natural question is whether we can combine them to build models that (1) perform better on all of the training datasets and (2) generalize and transfer better to new datasets. Prior work has addressed this goal by training one network simultaneously on multiple datasets, which works well on average but is prone to over- or under-fitting different sub-distributions and might transfer worse compared to source models with more overlap with the target dataset. Our approach is to model multi-dataset question answering with a collection of single-dataset experts, by training a collection of lightweight, dataset-specific adapter modules (Houlsby et al., 2019) that share an underlying Transformer model. We find that these Multi-Adapter Dataset Experts (MADE) outperform all our baselines in terms of in-distribution accuracy, and simple methods based on parameter-averaging lead to better zero-shot generalization and few-shot transfer performance, offering a strong and versatile starting point for building new reading comprehension systems.