 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Training of Partially Masked Neural Networks
Paper and Code
Jun 16, 2021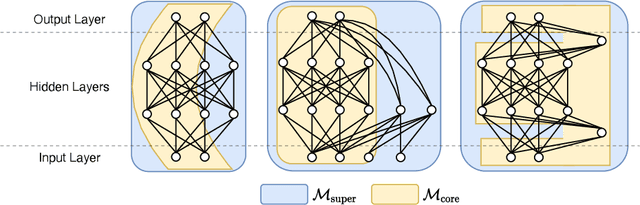


For deploying deep learning models to lower end devices, it is necessary to train less resource-demanding variants of state-of-the-art architectures. This does not eliminate the need for more expensive models as they have a higher performance. In order to avoid training two separate models, we show that it is possible to train neural networks in such a way that a predefined 'core' subnetwork can be split-off from the trained full network with remarkable good performance. We extend on prior methods that focused only on core networks of smaller width, while we focus on supporting arbitrary core network architectures. Our proposed training scheme switches consecutively between optimizing only the core part of the network and the full one. The accuracy of the full model remains comparable, while the core network achieves better performance than when it is trained in isolation. In particular, we show that training a Transformer with a low-rank core gives a low-rank model with superior performance than when training the low-rank model alone. We analyze our training scheme theoretically, and show its convergence under assumptions that are either standard or practically justified. Moreover, we show that the developed theoretical framework allows analyzing many other partial training schemes for neural networks.