 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulFlow: Simultaneously Extracting Feature and Identifying Target for Unsupervised Video Object Segmentation
Paper and Code
Nov 30, 2023

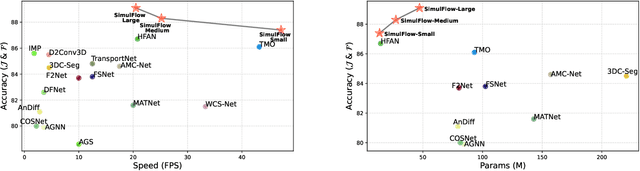

Unsupervised video object segmentation (UVOS) aims at detecting the primary objects in a given video sequence without any human interposing. Most existing methods rely on two-stream architectures that separately encode the appearance and motion information before fusing them to identify the target and generate object masks. However, this pipeline is computationally expensive and can lead to suboptimal performance due to the difficulty of fusing the two modalities properly. In this paper, we propose a novel UVOS model called SimulFlow that simultaneously performs feature extraction and target identification, enabling efficient and effective unsupervised video object segmentation. Concretely, we design a novel SimulFlow Attention mechanism to bridege the image and motion by utilizing the flexibility of attention operation, where coarse masks predicted from fused feature at each stage are used to constrain the attention operation within the mask area and exclude the impact of noise. Because of the bidirectional information flow between visual and optical flow features in SimulFlow Attention, no extra hand-designed fusing module is required and we only adopt a light decoder to obtain the final prediction. We evaluate our method on several benchmark datasets and achieve state-of-the-art results. Our proposed approach not only outperforms existing methods but also addresses the computational complexity and fusion difficulties caused by two-stream architectures. Our models achieve 87.4% J & F on DAVIS-16 with the highest speed (63.7 FPS on a 3090) and the lowest parameters (13.7 M). Our SimulFlow also obtains competitive results on video salient object detection datasets.