 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity Kernel and Clustering via Random Projection Forests
Paper and Code
Aug 28, 2019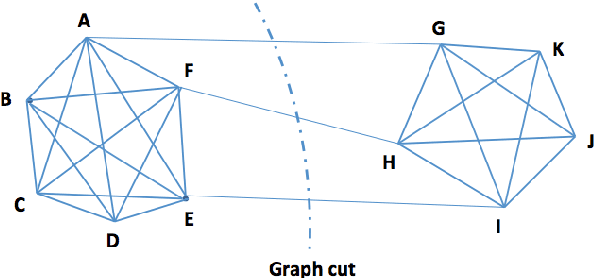
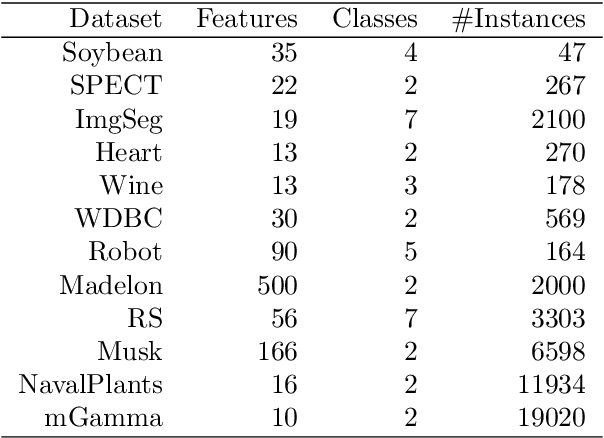

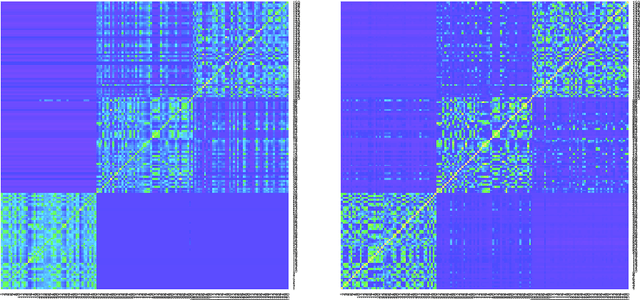
Similarity plays a fundamental role in many areas, including data mining, machine learning, statistics and various applied domains. Inspired by the success of ensemble methods and the flexibility of trees, we propose to learn a similarity kernel called rpf-kernel through random projection forests (rpForests). Our theoretical analysis reveals a highly desirable property of rpf-kernel: far-away (dissimilar) points have a low similarity value while nearby (similar) points would have a high similarity}, and the similarities have a native interpretation as the probability of points remaining in the same leaf nodes during the growth of rpForests. The learned rpf-kernel leads to an effective clustering algorithm--rpfCluster. On a wide variety of real and benchmark datasets, rpfCluster compares favorably to K-means clustering, spectral clustering and a state-of-the-art clustering ensemble algorithm--Cluster Forests. Our approach is simple to implement and readily adapt to the geometry of the underlying data. Given its desirable theoretical property and competitive empirical performance when applied to clustering, we expect rpf-kernel to be applicable to many problems of an unsupervised nature or as a regularizer in some supervised or weakly supervised settings.