 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Attend and Distill:Knowledge Distillation via Attention-based Feature Matching
Paper and Code
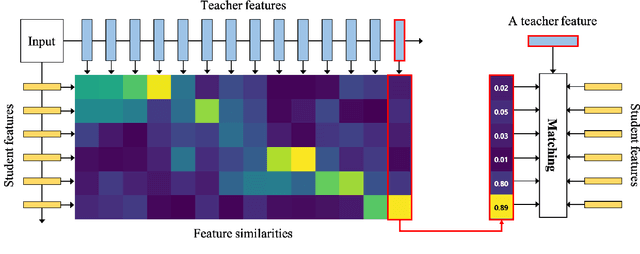
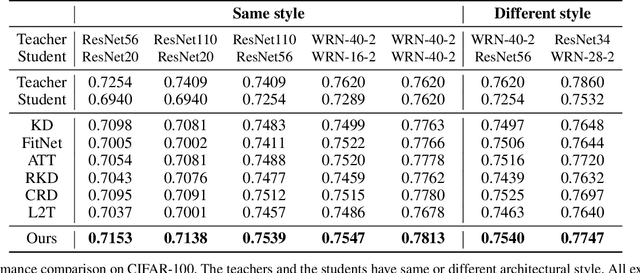
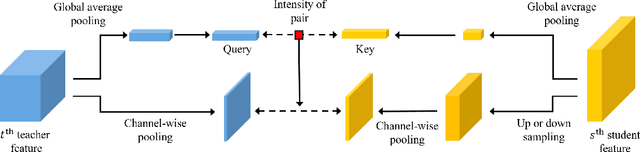
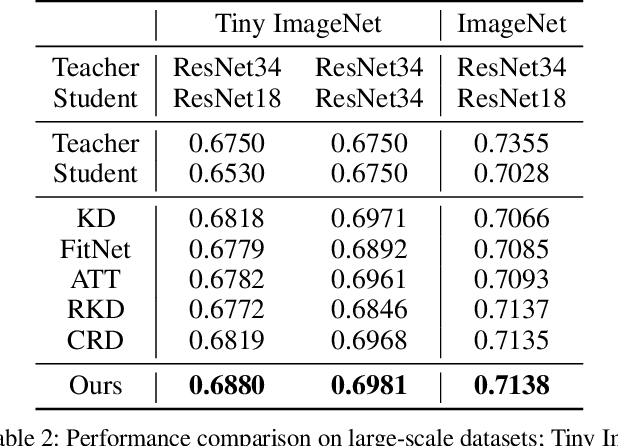
Knowledge distillation extracts general knowledge from a pre-trained teacher network and provides guidance to a target student network. Most studies manually tie intermediate features of the teacher and student, and transfer knowledge through pre-defined links. However, manual selection often constructs ineffective links that limit the improvement from the distillation. There has been an attempt to address the problem, but it is still challenging to identify effective links under practical scenarios. In this paper, we introduce an effective and efficient feature distillation method utilizing all the feature levels of the teacher without manually selecting the links. Specifically, our method utilizes an attention-based meta-network that learns relative similarities between features, and applies identified similarities to control distillation intensities of all possible pairs. As a result, our method determines competent links more efficiently than the previous approach and provides better performance on model compression and transfer learning tasks. Further qualitative analyses and ablative studies describe how our method contributes to better distillation. The implementation code is available at github.com/clovaai/attention-feature-distillation.