 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAS: Approaching optimal Segmentation for End-to-End Speech Translation
Paper and Code
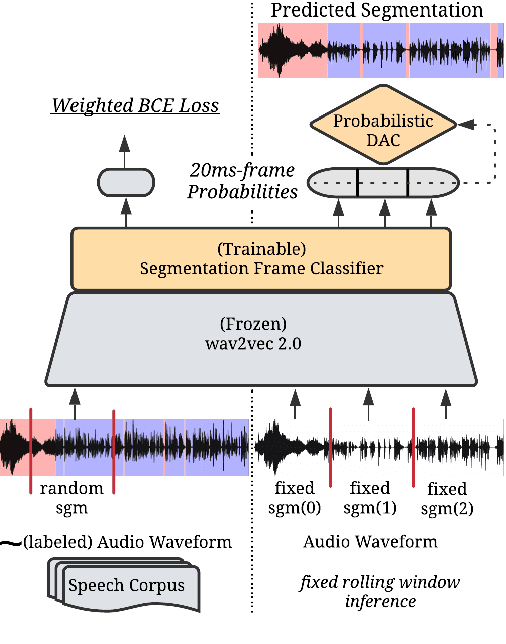
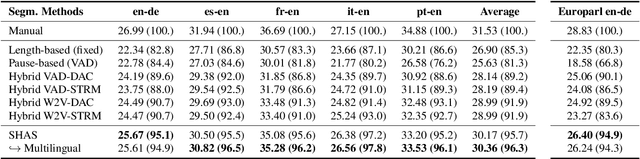
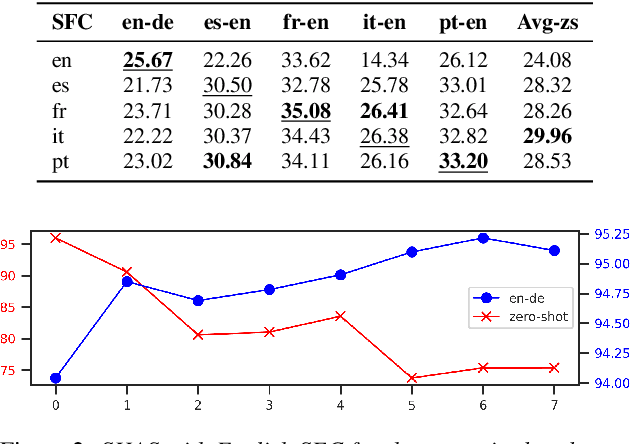
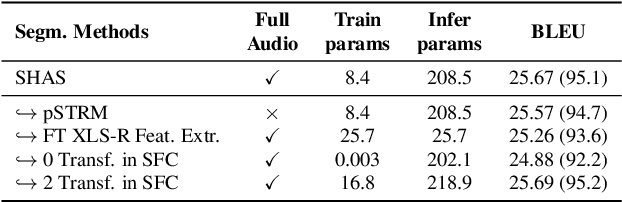
Speech translation models are unable to directly process long audios, like TED talks, which have to be split into shorter segments. Speech translation datasets provide manual segmentations of the audios, which are not available in real-world scenarios, and existing segmentation methods usually significantly reduce translation quality at inference time. To bridge the gap between the manual segmentation of training and the automatic one at inference, we propose Supervised Hybrid Audio Segmentation (SHAS), a method that can effectively learn the optimal segmentation from any manually segmented speech corpus. First, we train a classifier to identify the included frames in a segmentation, using speech representations from a pre-trained wav2vec 2.0. The optimal splitting points are then found by a probabilistic Divide-and-Conquer algorithm that progressively splits at the frame of lowest probability until all segments are below a pre-specified length. Experiments on MuST-C and mTEDx show that the translation of the segments produced by our method approaches the quality of the manual segmentation on 5 languages pairs. Namely, SHAS retains 95-98% of the manual segmentation's BLEU score, compared to the 87-93% of the best existing methods. Our method is additionally generalizable to different domains and achieves high zero-shot performance in unseen languages.