 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpened Generalization Bounds based on Conditional Mutual Information and an Application to Noisy, Iterative Algorithms
Paper and Code
Apr 27, 2020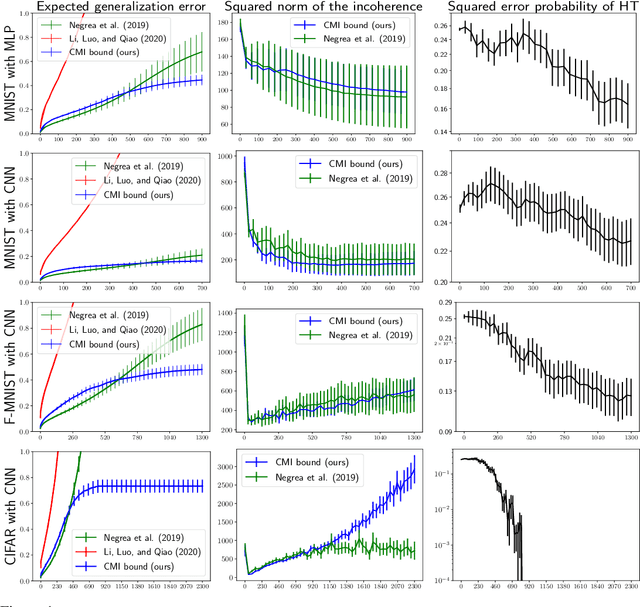
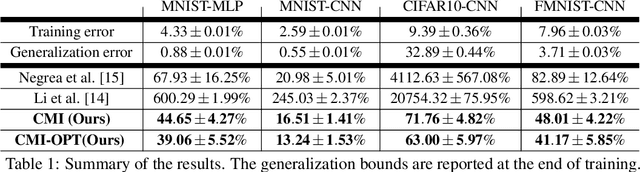
The information-theoretic framework of Russo and J. Zou (2016) and Xu and Raginsky (2017) provides bounds on the generalization error of a learning algorithm in terms of the mutual information between the algorithm's output and the training sample. In this work, we study the proposal, by Steinke and Zakynthinou (2020), to reason about the generalization error of a learning algorithm by introducing a super sample that contains the training sample as a random subset and computing mutual information conditional on the super sample. We first show that these new bounds based on the conditional mutual information are tighter than those based on the unconditional mutual information. We then introduce yet tighter bounds, building on the "individual sample" idea of Bu, S. Zou, and Veeravalli (2019) and the "data dependent" ideas of Negrea et al. (2019), using disintegrated mutual information. Finally, we apply these bounds to the study of Langevin dynamics algorithm, showing that conditioning on the super sample allows us to exploit information in the optimization trajectory to obtain tighter bounds based on hypothesis tests.