 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Representation Theorems for ReLU Networks with Precise Dependence on Depth
Paper and Code
Jun 07, 2020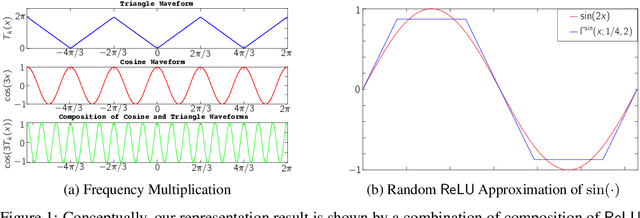
We prove sharp dimension-free representation results for neural networks with $D$ ReLU layers under square loss for a class of functions $\mathcal{G}_D$ defined in the paper. These results capture the precise benefits of depth in the following sense: 1. The rates for representing the class of functions $\mathcal{G}_D$ via $D$ ReLU layers is sharp up to constants, as shown by matching lower bounds. 2. For each $D$, $\mathcal{G}_{D} \subseteq \mathcal{G}_{D+1}$ and as $D$ grows the class of functions $\mathcal{G}_{D}$ contains progressively less smooth functions. 3. If $D^{\prime} < D$, then the approximation rate for the class $\mathcal{G}_D$ achieved by depth $D^{\prime}$ networks is strictly worse than that achieved by depth $D$ networks. This constitutes a fine-grained characterization of the representation power of feedforward networks of arbitrary depth $D$ and number of neurons $N$, in contrast to existing representation results which either require $D$ growing quickly with $N$ or assume that the function being represented is highly smooth. In the latter case similar rates can be obtained with a single nonlinear layer. Our results confirm the prevailing hypothesis that deeper networks are better at representing less smooth functions, and indeed, the main technical novelty is to fully exploit the fact that deep networks can produce highly oscillatory functions with few activation functions.