 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShare With Thy Neighbors: Single-View Reconstruction by Cross-Instance Consistency
Paper and Code
Apr 21, 2022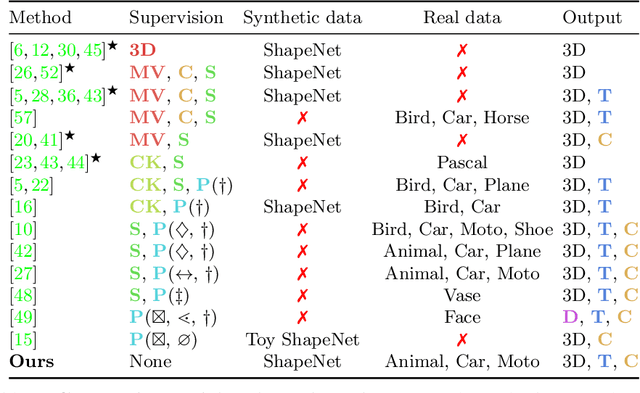
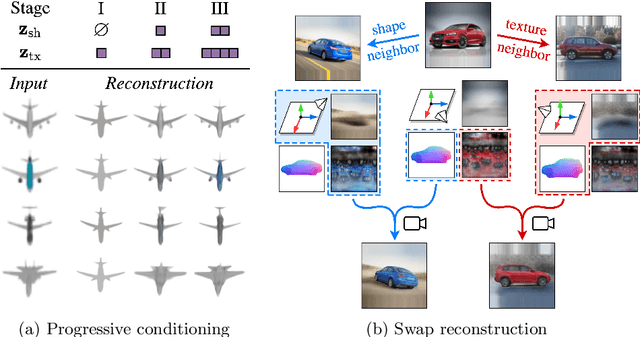
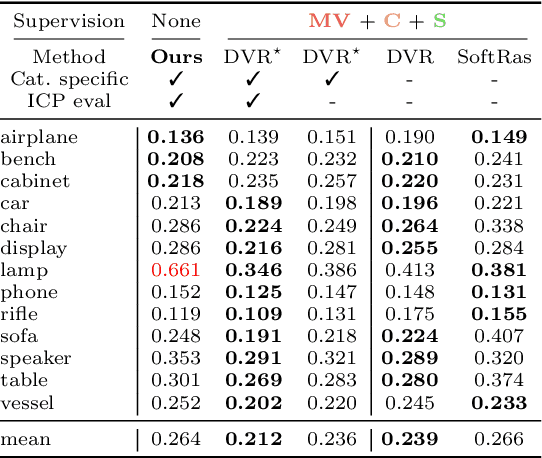
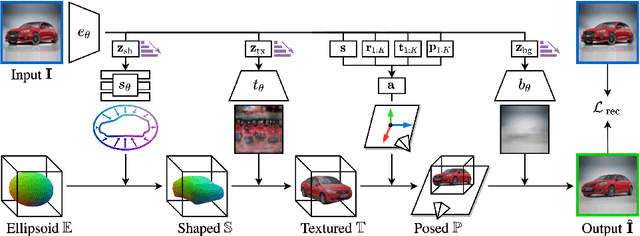
Approaches to single-view reconstruction typically rely on viewpoint annotations, silhouettes, the absence of background, multiple views of the same instance, a template shape, or symmetry. We avoid all of these supervisions and hypotheses by leveraging explicitly the consistency between images of different object instances. As a result, our method can learn from large collections of unlabelled images depicting the same object category. Our main contributions are two approaches to leverage cross-instance consistency: (i) progressive conditioning, a training strategy to gradually specialize the model from category to instances in a curriculum learning fashion; (ii) swap reconstruction, a loss enforcing consistency between instances having similar shape or texture. Critical to the success of our method are also: our structured autoencoding architecture decomposing an image into explicit shape, texture, pose, and background; an adapted formulation of differential rendering, and; a new optimization scheme alternating between 3D and pose learning. We compare our approach, UNICORN, both on the diverse synthetic ShapeNet dataset - the classical benchmark for methods requiring multiple views as supervision - and on standard real-image benchmarks (Pascal3D+ Car, CUB-200) for which most methods require known templates and silhouette annotations. We also showcase applicability to more challenging real-world collections (CompCars, LSUN), where silhouettes are not available and images are not cropped around the object.