 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAP values for Explaining CNN-based Text Classification Models
Paper and Code
Aug 26, 2020

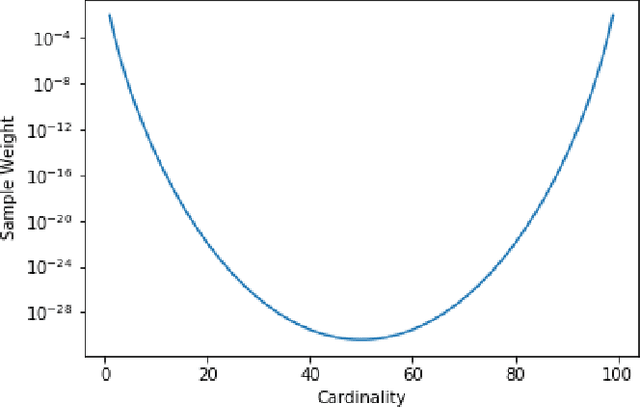

Deep neural networks are increasingly used in natural language processing (NLP) models. However, the need to interpret and explain the results from complex algorithms are limiting their widespread adoption in regulated industries such as banking. There has been recent work on interpretability of machine learning algorithms with structured data. But there are only limited techniques for NLP applications where the problem is more challenging due to the size of the vocabulary, high-dimensional nature, and the need to consider textual coherence and language structure. This paper develops a methodology to compute SHAP values for local explainability of CNN-based text classification models. The approach is also extended to compute global scores to assess the importance of features. The results are illustrated on sentiment analysis of Amazon Electronic Review data.