 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowSync: Performing Synchronization in the Background for Highly Scalable Distributed Training
Paper and Code
Mar 07, 2020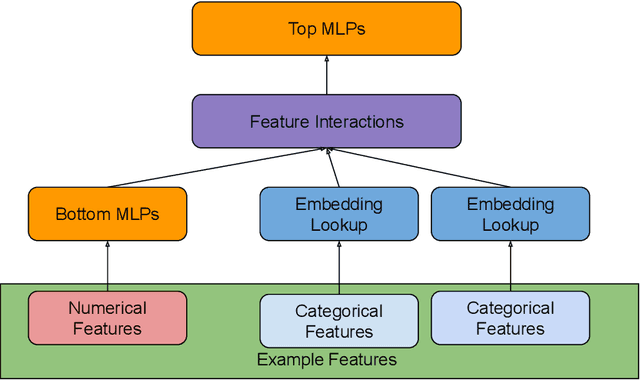
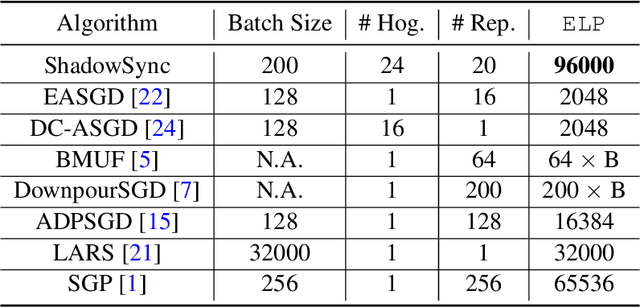
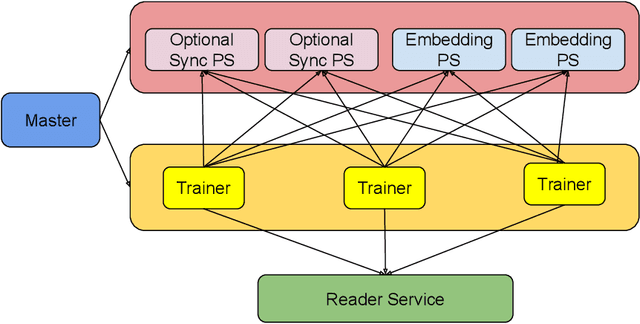
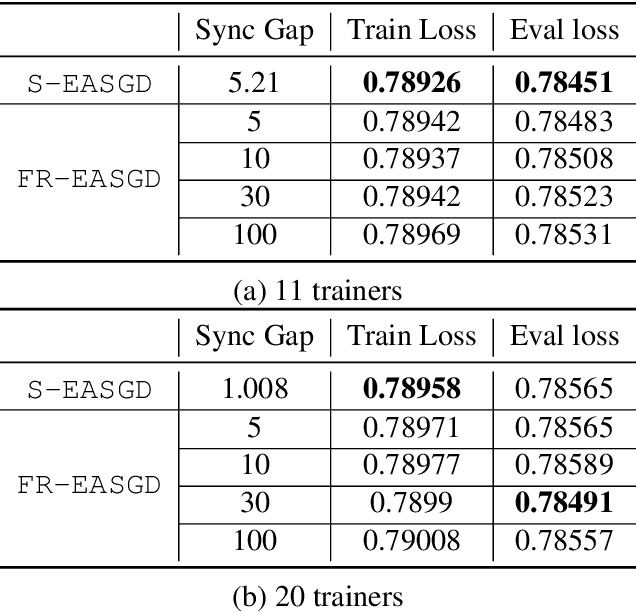
Distributed training is useful to train complicated models to shorten the training time. As each of the workers only sees a small fraction of data, workers need to synchronize on the parameter updates. One of the central questions in distributed training is how to parsimoniously synchronize parameters while preserving model quality. To address this problem, we propose the \textbf{ShadowSync} framework, in which we isolate synchronization from training and run it in the background. In contrast to common strategies including synchronous stochastic gradient descent (SGD), asynchronous SGD, and model averaging on independently trained sub-models, where synchronization happens in the foreground, ShadowSync synchronization is neither part of the backward pass, nor happens every $k$ iterations. Our framework is generic to host various types of synchronization algorithms, and we propose 3 approaches under this theme. The superiority of ShadowSync is confirmed by experiments on training deep neural networks for click-through-rate prediction. Our methods all succeed in making the training throughput linearly scale with the number of trainers. Comparing to their foreground counterparts, our methods exhibit neutral to better model quality and better scalability when we keep the number of parameter servers the same. In our training system which expresses both replication and Hogwild parallelism, ShadowSync also accomplishes the highest example level parallelism number comparing to the prior arts.