 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD-QA: Fast Schema-Guided Dialogue State Tracking for Unseen Services
Paper and Code


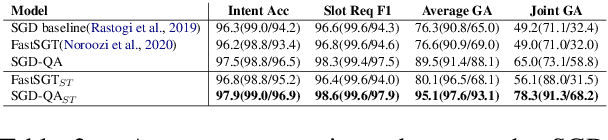

Dialogue state tracking is an essential part of goal-oriented dialogue systems, while most of these state tracking models often fail to handle unseen services. In this paper, we propose SGD-QA, a simple and extensible model for schema-guided dialogue state tracking based on a question answering approach. The proposed multi-pass model shares a single encoder between the domain information and dialogue utterance. The domain's description represents the query and the dialogue utterance serves as the context. The model improves performance on unseen services by at least 1.6x compared to single-pass baseline models on the SGD dataset. SGD-QA shows competitive performance compared to state-of-the-art multi-pass models while being significantly more efficient in terms of memory consumption and training performance. We provide a thorough discussion on the model with ablation study and error analysis.