Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Feature Classification in the Context of Redundancies
Paper and Code
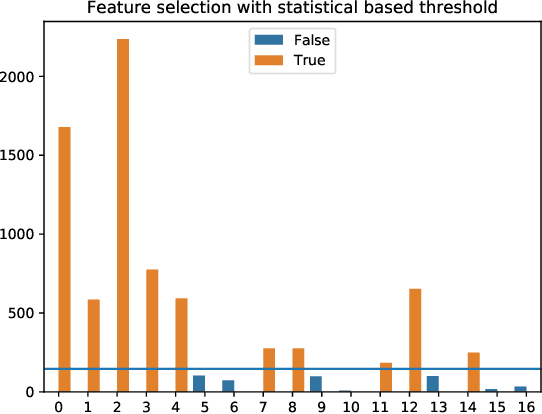
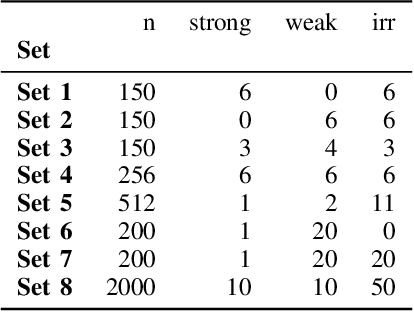
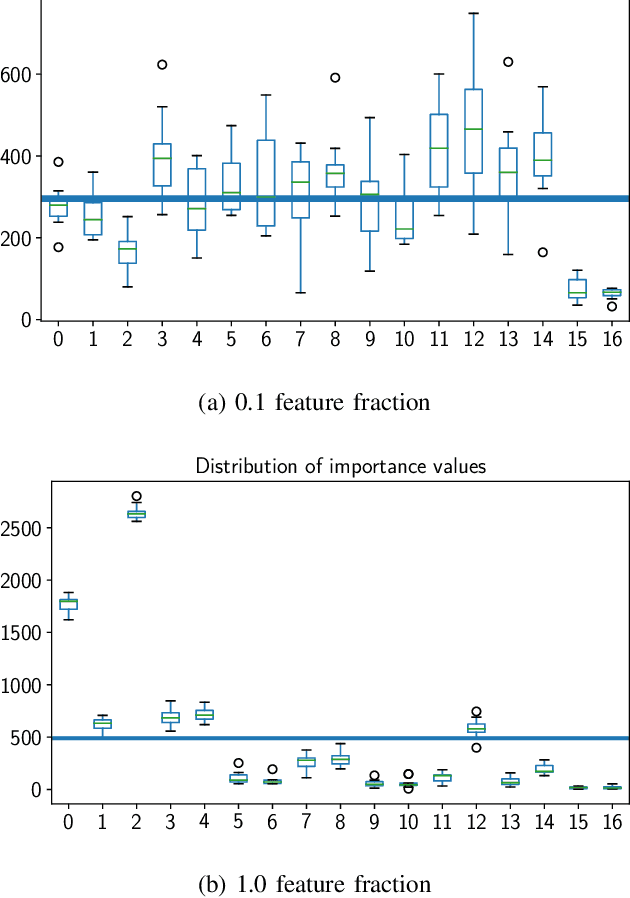
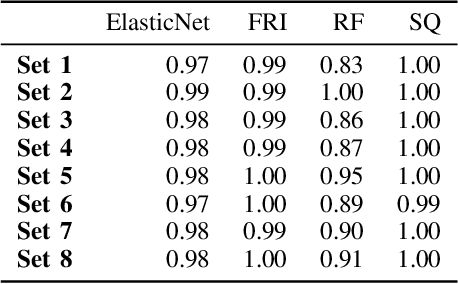
The problem of all-relevant feature selection is concerned with finding a relevant feature set with preserved redundancies. There exist several approximations to solve this problem but only one could give a distinction between strong and weak relevance. This approach was limited to the case of linear problems. In this work, we present a new solution for this distinction in the non-linear case through the use of random forest models and statistical methods.
* Added new experiment and footnote to reproducable results
View paper on