 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Lexical Normalization with Multilingual Transformers
Paper and Code
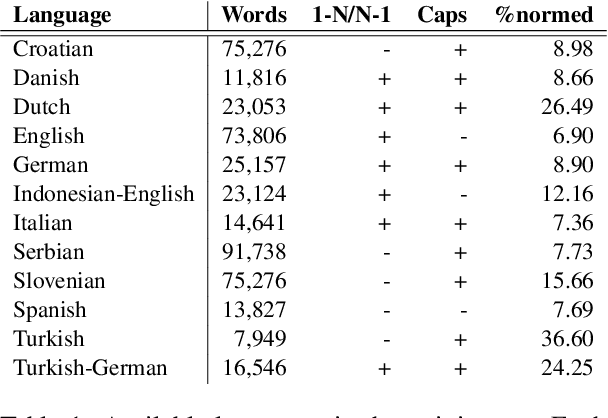
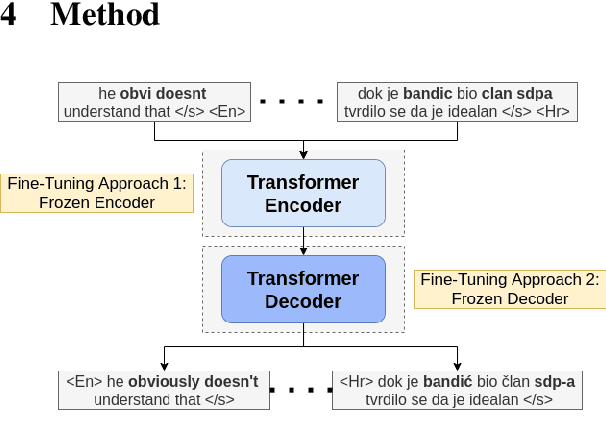

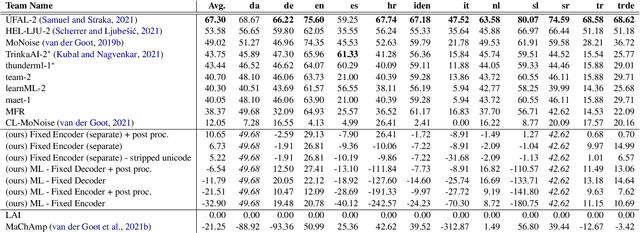
Current benchmark tasks for natural language processing contain text that is qualitatively different from the text used in informal day to day digital communication. This discrepancy has led to severe performance degradation of state-of-the-art NLP models when fine-tuned on real-world data. One way to resolve this issue is through lexical normalization, which is the process of transforming non-standard text, usually from social media, into a more standardized form. In this work, we propose a sentence-level sequence-to-sequence model based on mBART, which frames the problem as a machine translation problem. As the noisy text is a pervasive problem across languages, not just English, we leverage the multi-lingual pre-training of mBART to fine-tune it to our data. While current approaches mainly operate at the word or subword level, we argue that this approach is straightforward from a technical standpoint and builds upon existing pre-trained transformer networks. Our results show that while word-level, intrinsic, performance evaluation is behind other methods, our model improves performance on extrinsic, downstream tasks through normalization compared to models operating on raw, unprocessed, social media text.