 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq2Edits: Sequence Transduction Using Span-level Edit Operations
Paper and Code
Sep 23, 2020
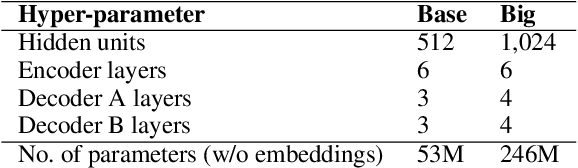


We propose Seq2Edits, an open-vocabulary approach to sequence editing for natural language processing (NLP) tasks with a high degree of overlap between input and output texts. In this approach, each sequence-to-sequence transduction is represented as a sequence of edit operations, where each operation either replaces an entire source span with target tokens or keeps it unchanged. We evaluate our method on five NLP tasks (text normalization, sentence fusion, sentence splitting & rephrasing, text simplification, and grammatical error correction) and report competitive results across the board. For grammatical error correction, our method speeds up inference by up to 5.2x compared to full sequence models because inference time depends on the number of edits rather than the number of target tokens. For text normalization, sentence fusion, and grammatical error correction, our approach improves explainability by associating each edit operation with a human-readable tag.