 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language
Paper and Code
Jun 09, 2024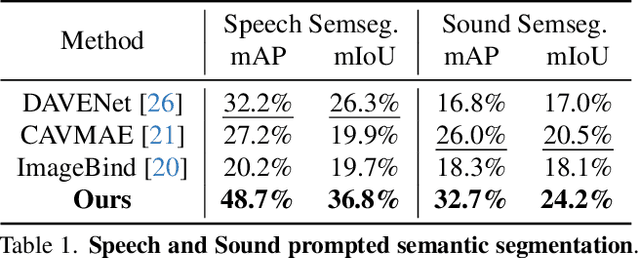
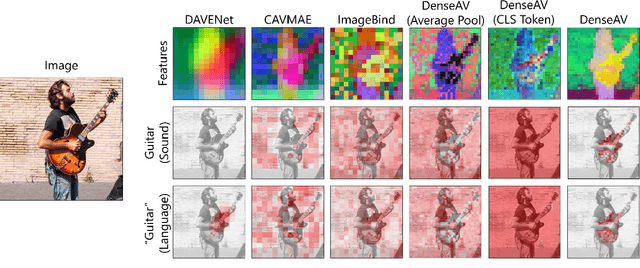
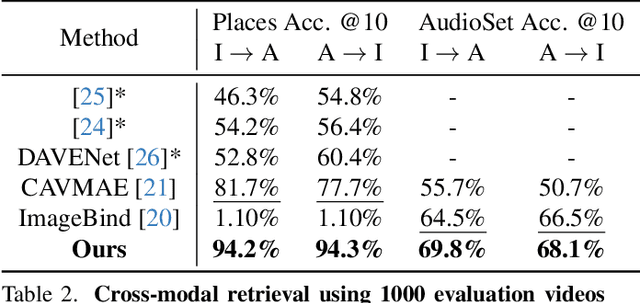
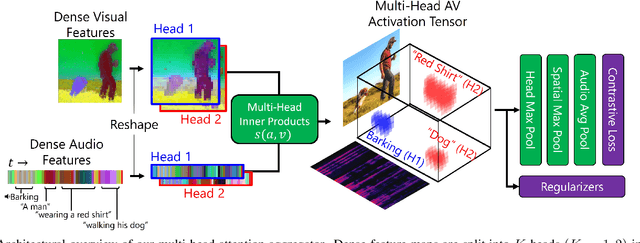
We present DenseAV, a novel dual encoder grounding architecture that learns high-resolution, semantically meaningful, and audio-visually aligned features solely through watching videos. We show that DenseAV can discover the ``meaning'' of words and the ``location'' of sounds without explicit localization supervision. Furthermore, it automatically discovers and distinguishes between these two types of associations without supervision. We show that DenseAV's localization abilities arise from a new multi-head feature aggregation operator that directly compares dense image and audio representations for contrastive learning. In contrast, many other systems that learn ``global'' audio and video representations cannot localize words and sound. Finally, we contribute two new datasets to improve the evaluation of AV representations through speech and sound prompted semantic segmentation. On these and other datasets we show DenseAV dramatically outperforms the prior art on speech and sound prompted semantic segmentation. DenseAV outperforms the previous state-of-the-art, ImageBind, on cross-modal retrieval using fewer than half of the parameters. Project Page: \href{https://aka.ms/denseav}{https://aka.ms/denseav}