 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparate, Dynamic and Differentiable (SMART) Pruner for Block/Output Channel Pruning on Computer Vision Tasks
Paper and Code
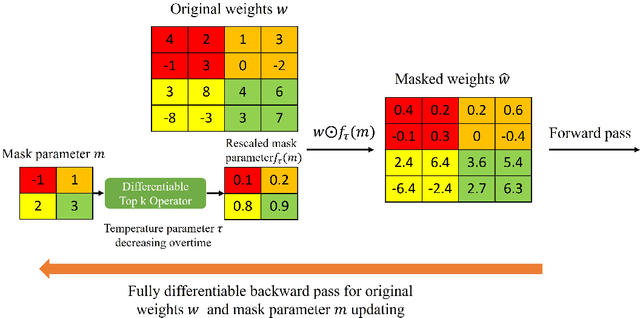


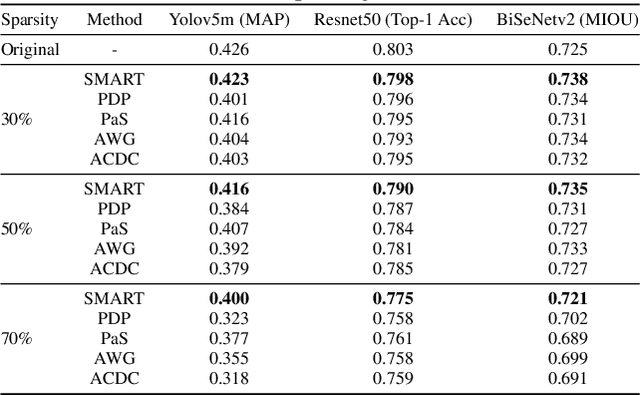
Deep Neural Network (DNN) pruning has emerged as a key strategy to reduce model size, improve inference latency, and lower power consumption on DNN accelerators. Among various pruning techniques, block and output channel pruning have shown significant potential in accelerating hardware performance. However, their accuracy often requires further improvement. In response to this challenge, we introduce a separate, dynamic and differentiable (SMART) pruner. This pruner stands out by utilizing a separate, learnable probability mask for weight importance ranking, employing a differentiable Top k operator to achieve target sparsity, and leveraging a dynamic temperature parameter trick to escape from non-sparse local minima. In our experiments, the SMART pruner consistently demonstrated its superiority over existing pruning methods across a wide range of tasks and models on block and output channel pruning. Additionally, we extend our testing to Transformer-based models in N:M pruning scenarios, where SMART pruner also yields state-of-the-art results, demonstrating its adaptability and robustness across various neural network architectures, and pruning types.