 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity of sparse codes to image distortions
Paper and Code
Apr 15, 2022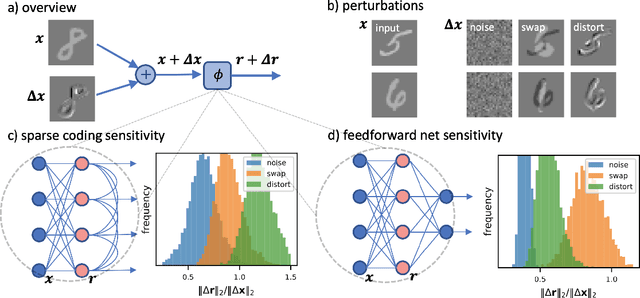
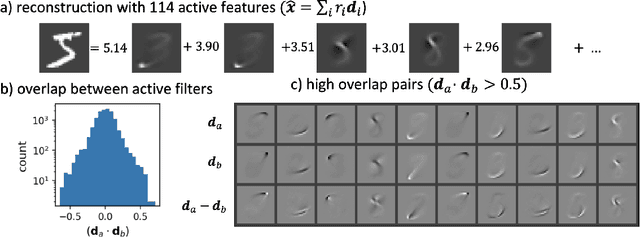
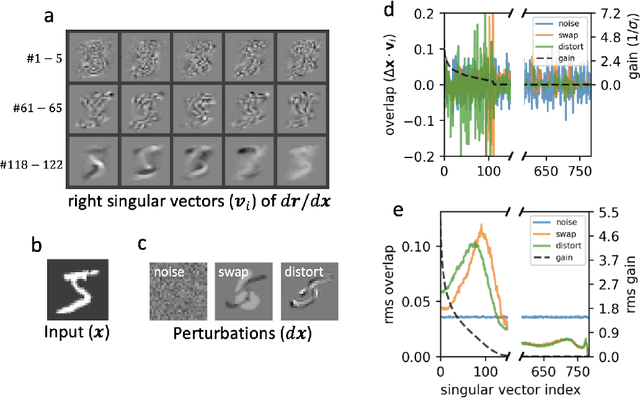
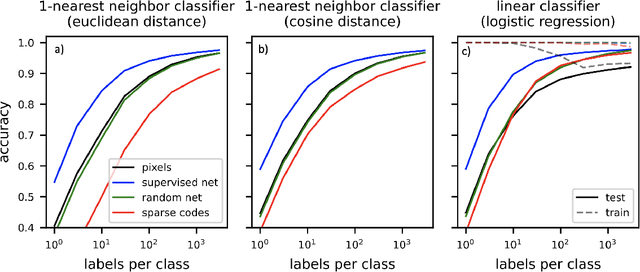
Sparse coding has been proposed as a theory of visual cortex and as an unsupervised algorithm for learning representations. We show empirically with the MNIST dataset that sparse codes can be very sensitive to image distortions, a behavior that may hinder invariant object recognition. A locally linear analysis suggests that the sensitivity is due to the existence of linear combinations of active dictionary elements with high cancellation. A nearest neighbor classifier is shown to perform worse on sparse codes than original images. For a linear classifier with a sufficiently large number of labeled examples, sparse codes are shown to yield higher accuracy than original images, but no higher than a representation computed by a random feedforward net. Sensitivity to distortions seems to be a basic property of sparse codes, and one should be aware of this property when applying sparse codes to invariant object recognition.