Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMIE: SEMantically Infused Embeddings with Enhanced Interpretability for Domain-specific Small Corpus
Paper and Code
Mar 21, 2021
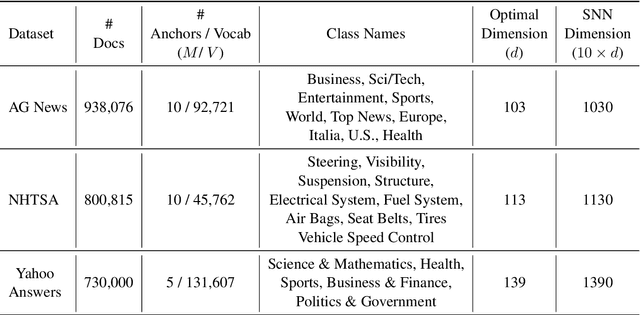
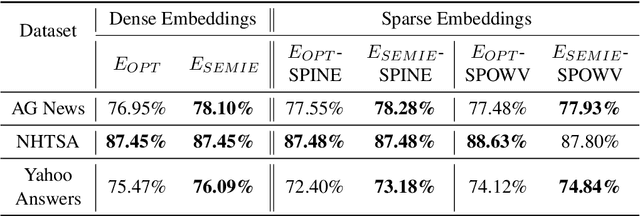
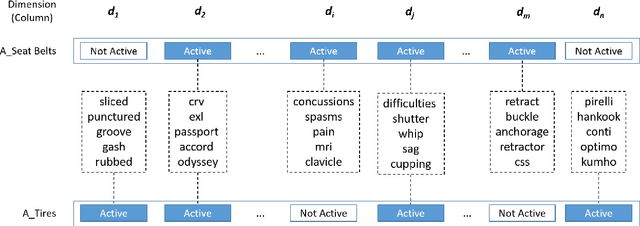
Word embeddings are a basic building block of modern NLP pipelines. Efforts have been made to learn rich, efficient, and interpretable embeddings for large generic datasets available in the public domain. However, these embeddings have limited applicability for small corpora from specific domains such as automotive, manufacturing, maintenance and support, etc. In this work, we present a comprehensive notion of interpretability for word embeddings and propose a novel method to generate highly interpretable and efficient embeddings for a domain-specific small corpus. We report the evaluation results of our resulting word embeddings and demonstrate their novel features for enhanced interpretability.
View paper on