 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Singing Voice Separation with Noisy Self-Training
Paper and Code
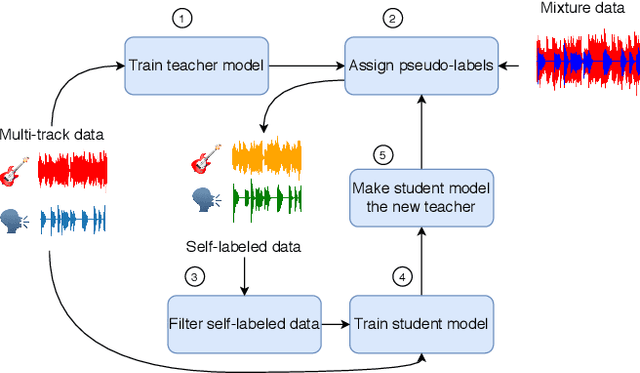
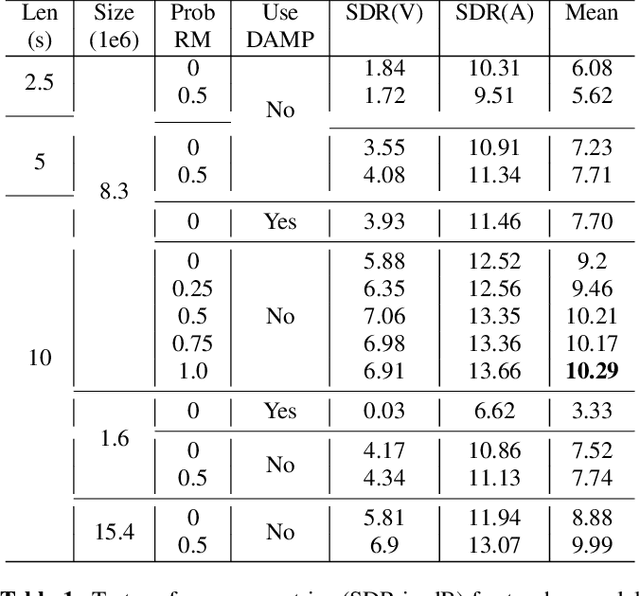
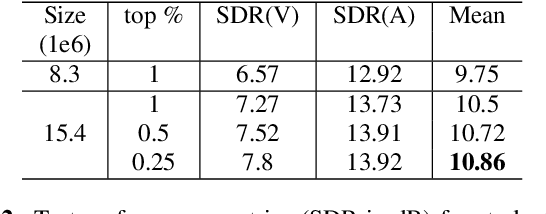
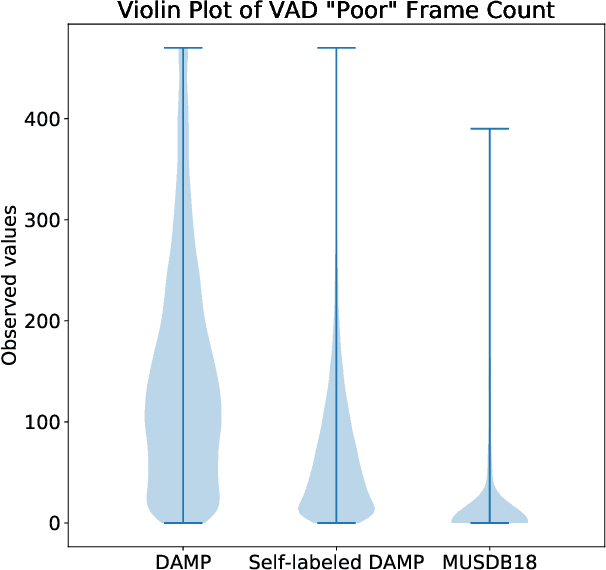
Recent progress in singing voice separation has primarily focused on supervised deep learning methods. However, the scarcity of ground-truth data with clean musical sources has been a problem for long. Given a limited set of labeled data, we present a method to leverage a large volume of unlabeled data to improve the model's performance. Following the noisy self-training framework, we first train a teacher network on the small labeled dataset and infer pseudo-labels from the large corpus of unlabeled mixtures. Then, a larger student network is trained on combined ground-truth and self-labeled datasets. Empirical results show that the proposed self-training scheme, along with data augmentation methods, effectively leverage the large unlabeled corpus and obtain superior performance compared to supervised methods.