 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised sequence classification through change point detection
Paper and Code
Oct 06, 2020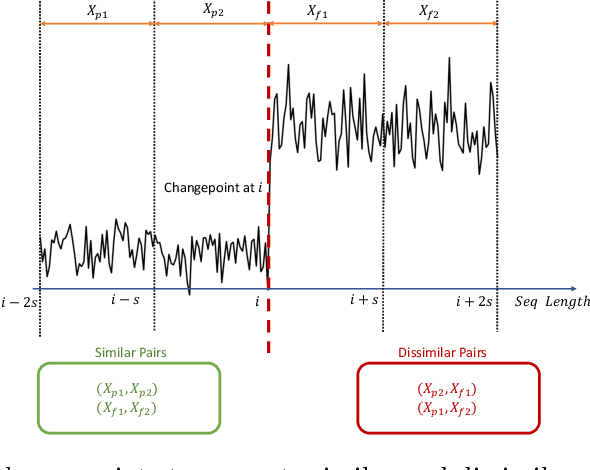

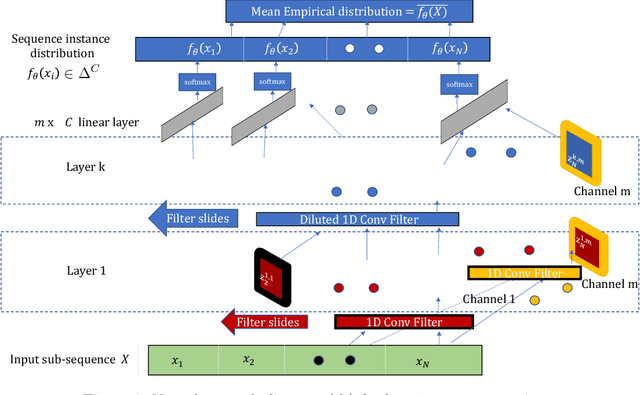

Sequential sensor data is generated in a wide variety of practical applications. A fundamental challenge involves learning effective classifiers for such sequential data. While deep learning has led to impressive performance gains in recent years in domains such as speech, this has relied on the availability of large datasets of sequences with high-quality labels. In many applications, however, the associated class labels are often extremely limited, with precise labelling/segmentation being too expensive to perform at a high volume. However, large amounts of unlabeled data may still be available. In this paper we propose a novel framework for semi-supervised learning in such contexts. In an unsupervised manner, change point detection methods can be used to identify points within a sequence corresponding to likely class changes. We show that change points provide examples of similar/dissimilar pairs of sequences which, when coupled with labeled, can be used in a semi-supervised classification setting. Leveraging the change points and labeled data, we form examples of similar/dissimilar sequences to train a neural network to learn improved representations for classification. We provide extensive synthetic simulations and show that the learned representations are superior to those learned through an autoencoder and obtain improved results on both simulated and real-world human activity recognition datasets.