 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised learning and the question of true versus estimated propensity scores
Paper and Code
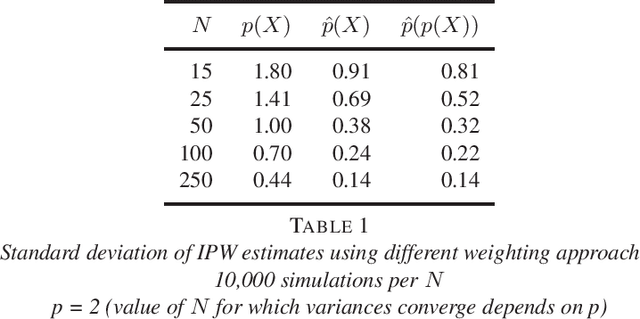
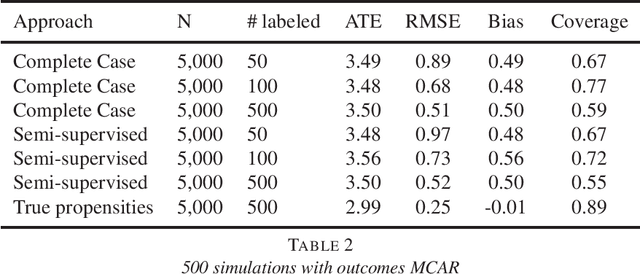
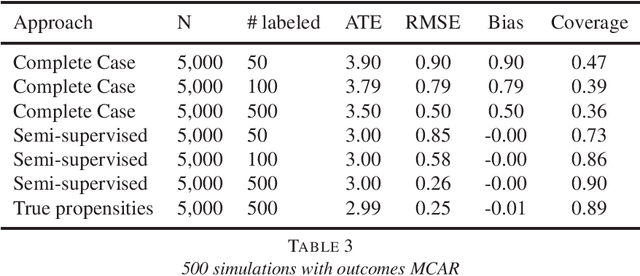
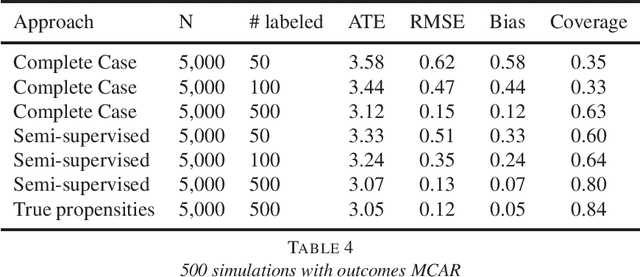
A straightforward application of semi-supervised machine learning to the problem of treatment effect estimation would be to consider data as "unlabeled" if treatment assignment and covariates are observed but outcomes are unobserved. According to this formulation, large unlabeled data sets could be used to estimate a high dimensional propensity function and causal inference using a much smaller labeled data set could proceed via weighted estimators using the learned propensity scores. In the limiting case of infinite unlabeled data, one may estimate the high dimensional propensity function exactly. However, longstanding advice in the causal inference community suggests that estimated propensity scores (from labeled data alone) are actually preferable to true propensity scores, implying that the unlabeled data is actually useless in this context. In this paper we examine this paradox and propose a simple procedure that reconciles the strong intuition that a known propensity functions should be useful for estimating treatment effects with the previous literature suggesting otherwise. Further, simulation studies suggest that direct regression may be preferable to inverse-propensity weight estimators in many circumstances.