Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised learning
Paper and Code
Dec 15, 2017
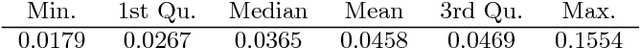
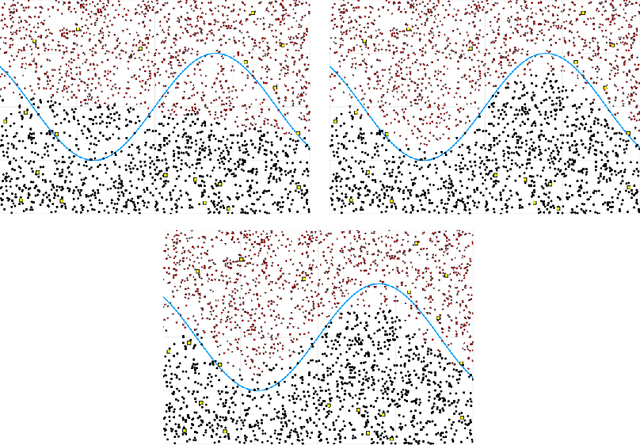
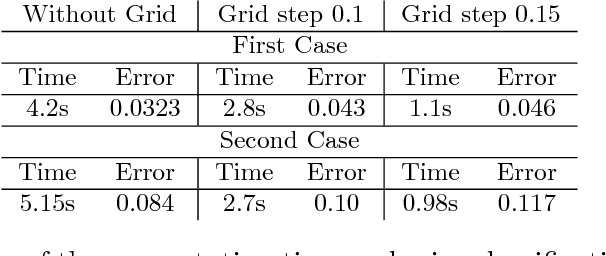
Semi-supervised learning deals with the problem of how, if possible, to take advantage of a huge amount of not classified data, to perform classification, in situations when, typically, the labelled data are few. Even though this is not always possible (it depends on how useful is to know the distribution of the unlabelled data in the inference of the labels), several algorithm have been proposed recently. A new algorithm is proposed, that under almost neccesary conditions, attains asymptotically the performance of the best theoretical rule, when the size of unlabeled data tends to infinity. The set of necessary assumptions, although reasonables, show that semi-parametric classification only works for very well conditioned problems.
* The paper as it is now, contains some mistakes in the proofs.
Hopefully soon I will submit a new version
View paper on