 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised K-means++
Paper and Code
Feb 01, 2016


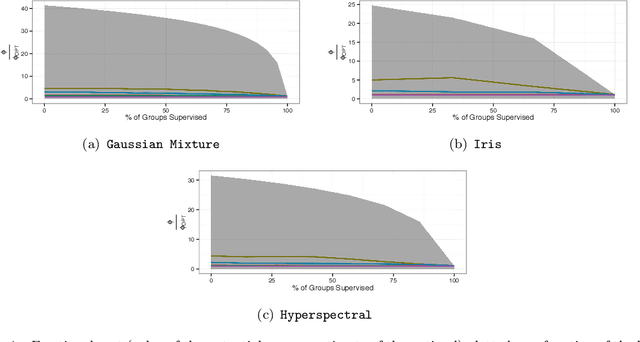
Traditionally, practitioners initialize the {\tt k-means} algorithm with centers chosen uniformly at random. Randomized initialization with uneven weights ({\tt k-means++}) has recently been used to improve the performance over this strategy in cost and run-time. We consider the k-means problem with semi-supervised information, where some of the data are pre-labeled, and we seek to label the rest according to the minimum cost solution. By extending the {\tt k-means++} algorithm and analysis to account for the labels, we derive an improved theoretical bound on expected cost and observe improved performance in simulated and real data examples. This analysis provides theoretical justification for a roughly linear semi-supervised clustering algorithm.