 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Audio Classification with Partially Labeled Data
Paper and Code

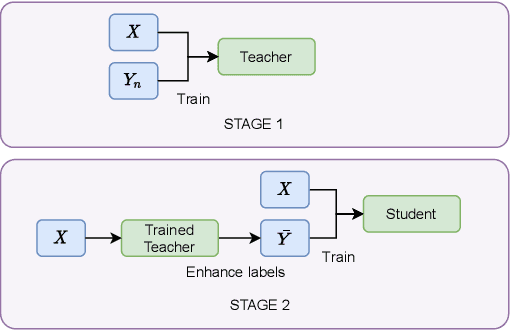
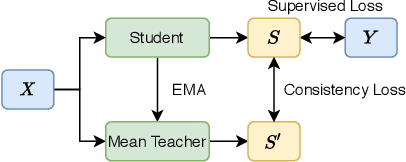
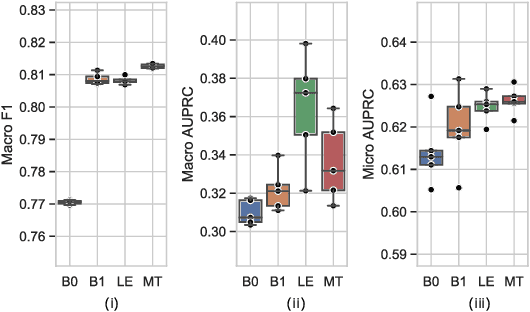
Audio classification has seen great progress with the increasing availability of large-scale datasets. These large datasets, however, are often only partially labeled as collecting full annotations is a tedious and expensive process. This paper presents two semi-supervised methods capable of learning with missing labels and evaluates them on two publicly available, partially labeled datasets. The first method relies on label enhancement by a two-stage teacher-student learning process, while the second method utilizes the mean teacher semi-supervised learning algorithm. Our results demonstrate the impact of improperly handling missing labels and compare the benefits of using different strategies leveraging data with few labels. Methods capable of learning with partially labeled data have the potential to improve models for audio classification by utilizing even larger amounts of data without the need for complete annotations.