 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics to Space(S2S): Embedding semantics into spatial space for zero-shot verb-object query inferencing
Paper and Code
Jun 13, 2019
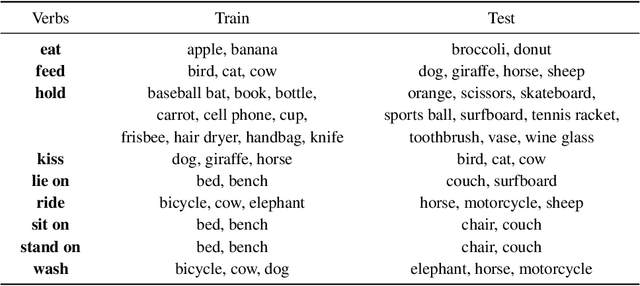
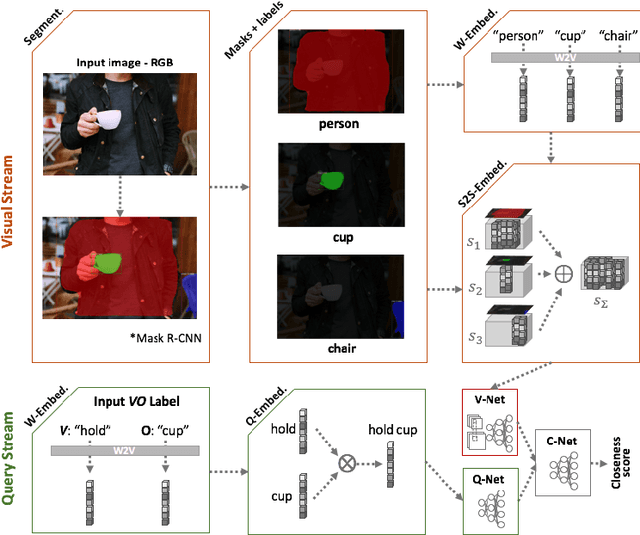

We present a novel deep zero-shot learning (ZSL) model for inferencing human-object-interaction with verb-object (VO) query. While the previous ZSL approaches only use the semantic/textual information to be fed into the query stream, we seek to incorporate and embed the semantics into the visual representation stream as well. Our approach is powered by Semantics-to-Space (S2S) architecture where semantics derived from the residing objects are embedded into a spatial space. This architecture allows the co-capturing of the semantic attributes of the human and the objects along with their location/size/silhouette information. As this is the first attempt to address the zero-shot human-object-interaction inferencing with VO query, we have constructed a new dataset, Verb-Transferability 60 (VT60). VT60 provides 60 different VO pairs with overlapping verbs tailored for testing ZSL approaches with VO query. Experimental evaluations show that our approach not only outperforms the state-of-the-art, but also shows the capability of consistently improving performance regardless of which ZSL baseline architecture is used.