 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Fruits on Multi-sensor Fused Data in Natural Orchards
Paper and Code
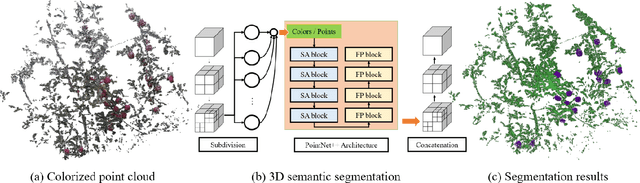
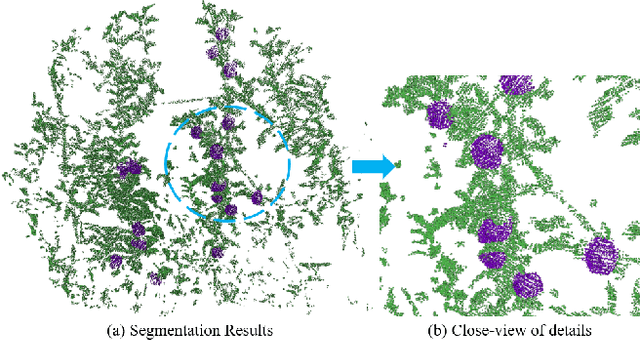


Semantic segmentation is a fundamental task for agricultural robots to understand the surrounding environments in natural orchards. The recent development of the LiDAR techniques enables the robot to acquire accurate range measurements of the view in the unstructured orchards. Compared to RGB images, 3D point clouds have geometrical properties. By combining the LiDAR and camera, rich information on geometries and textures can be obtained. In this work, we propose a deep-learning-based segmentation method to perform accurate semantic segmentation on fused data from a LiDAR-Camera visual sensor. Two critical problems are explored and solved in this work. The first one is how to efficiently fused the texture and geometrical features from multi-sensor data. The second one is how to efficiently train the 3D segmentation network under severely imbalance class conditions. Moreover, an implementation of 3D segmentation in orchards including LiDAR-Camera data fusion, data collection and labelling, network training, and model inference is introduced in detail. In the experiment, we comprehensively analyze the network setup when dealing with highly unstructured and noisy point clouds acquired from an apple orchard. Overall, our proposed method achieves 86.2% mIoU on the segmentation of fruits on the high-resolution point cloud (100k-200k points). The experiment results show that the proposed method can perform accurate segmentation in real orchard environments.